We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
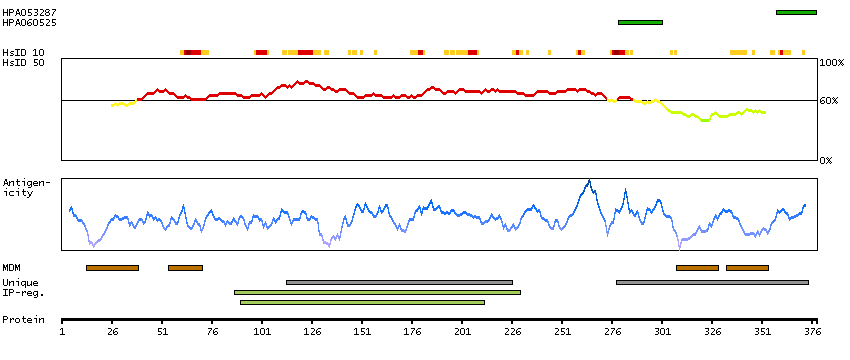
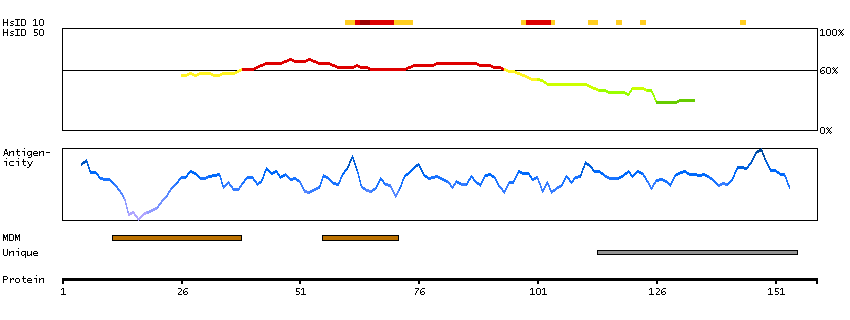
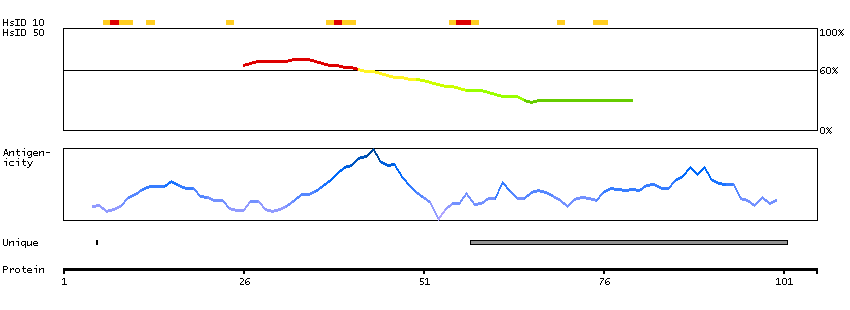
This gene encodes a member of the 1-acylglycerol-3-phosphate O-acyltransferase family. This integral membrane protein converts lysophosphatidic acid to phosphatidic acid, the second step in de novo phospholipid biosynthesis. [provided by RefSeq, Jul 2008]