We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
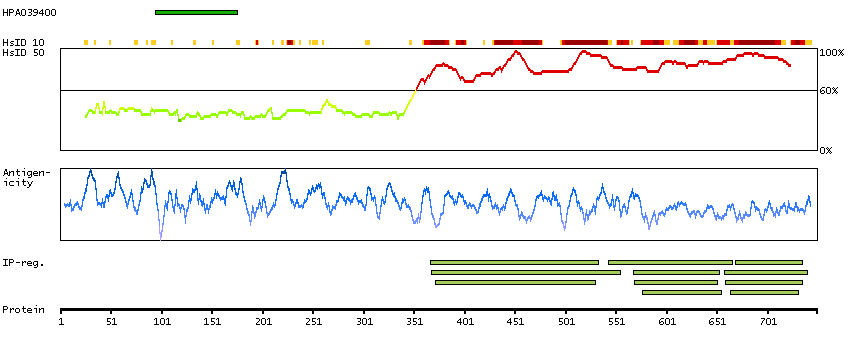
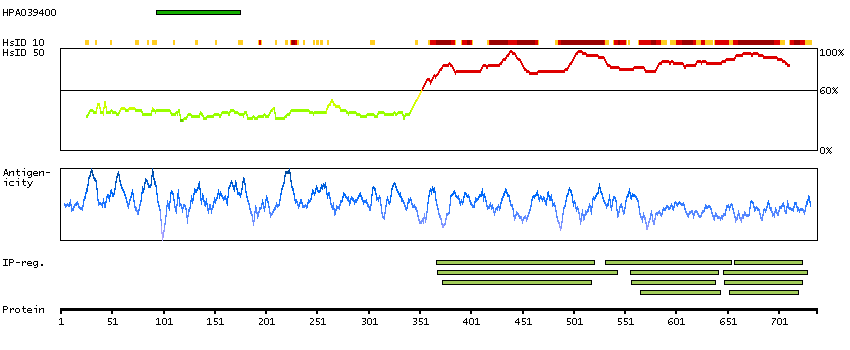
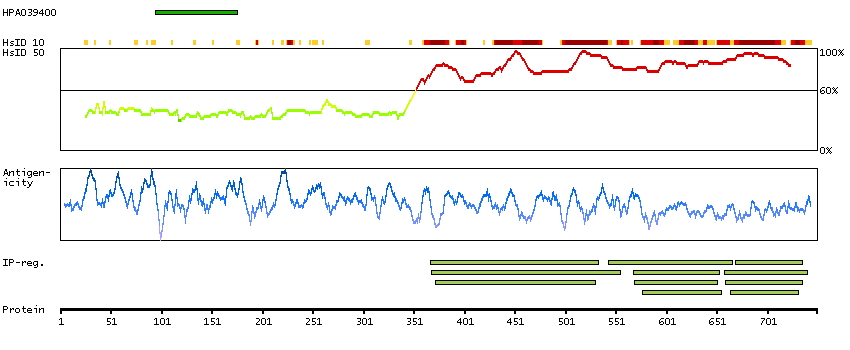
Amyloid beta (A4) precursor protein-binding, family A, member 2 (HGNC Symbol)
Entrez gene summary
The protein encoded by this gene is a member of the X11 protein family. It is a neuronal adapter protein that interacts with the Alzheimer's disease amyloid precursor protein (APP). It stabilizes APP and inhibits production of proteolytic APP fragments including the A beta peptide that is deposited in the brains of Alzheimer's disease patients. This gene product is believed to be involved in signal transduction processes. It is also regarded as a putative vesicular trafficking protein in the brain that can form a complex with the potential to couple synaptic vesicle exocytosis to neuronal cell adhesion. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Jul 2008]