We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
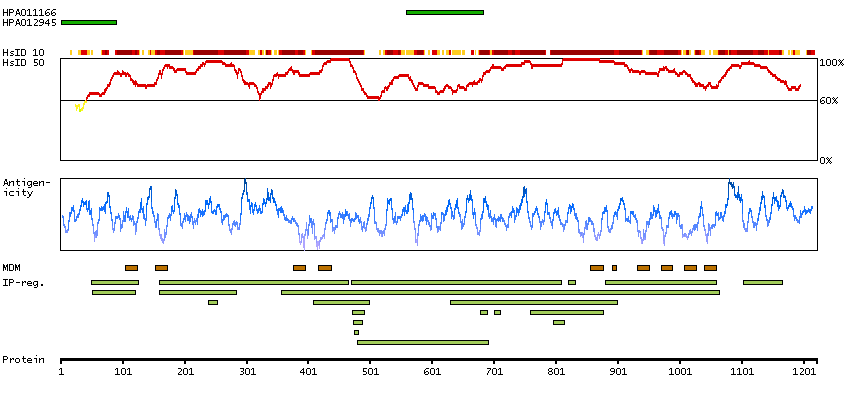
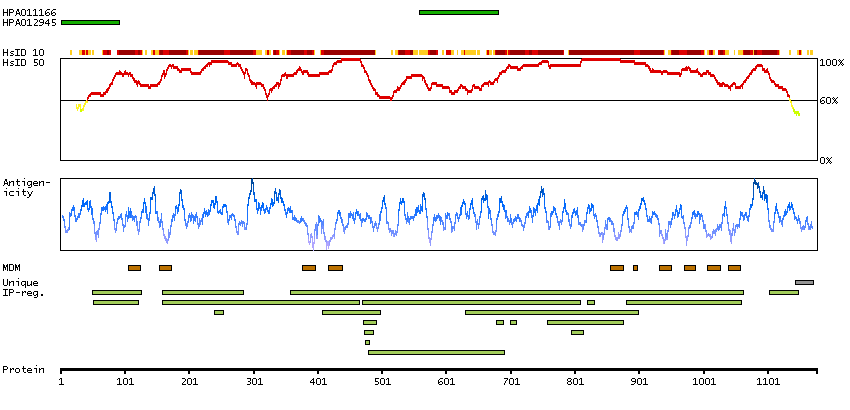
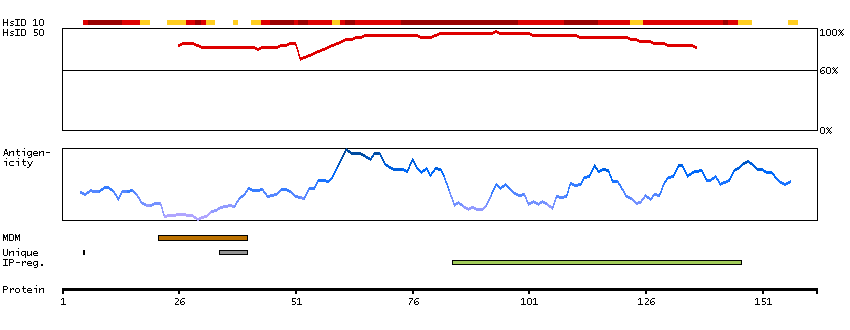
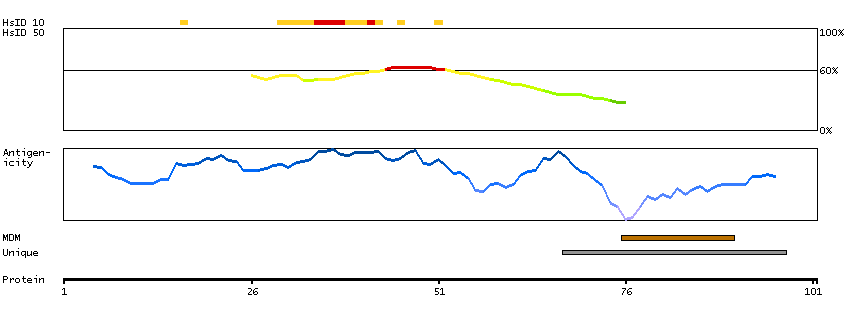
The protein encoded by this gene belongs to the family of P-type primary ion transport ATPases characterized by the formation of an aspartyl phosphate intermediate during the reaction cycle. These enzymes remove bivalent calcium ions from eukaryotic cells against very large concentration gradients and play a critical role in intracellular calcium homeostasis. The mammalian plasma membrane calcium ATPase isoforms are encoded by at least four separate genes and the diversity of these enzymes is further increased by alternative splicing of transcripts. The expression of different isoforms and splice variants is regulated in a developmental, tissue- and cell type-specific manner, suggesting that these pumps are functionally adapted to the physiological needs of particular cells and tissues. This gene encodes the plasma membrane calcium ATPase isoform 1. Alternatively spliced transcript variants encoding different isoforms have been identified. [provided by RefSeq, Jul 2008]