We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
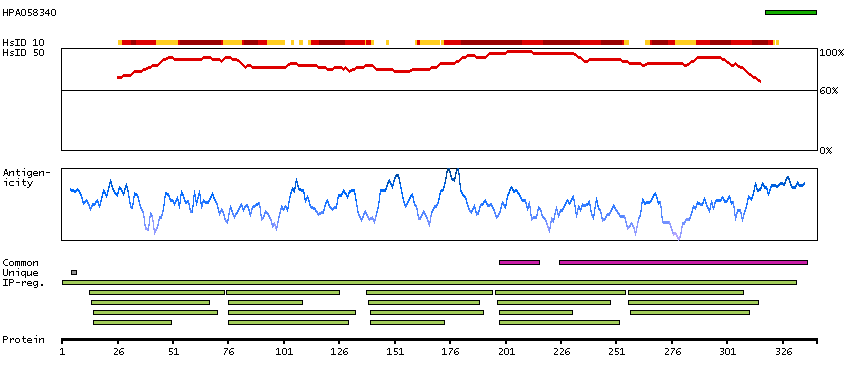
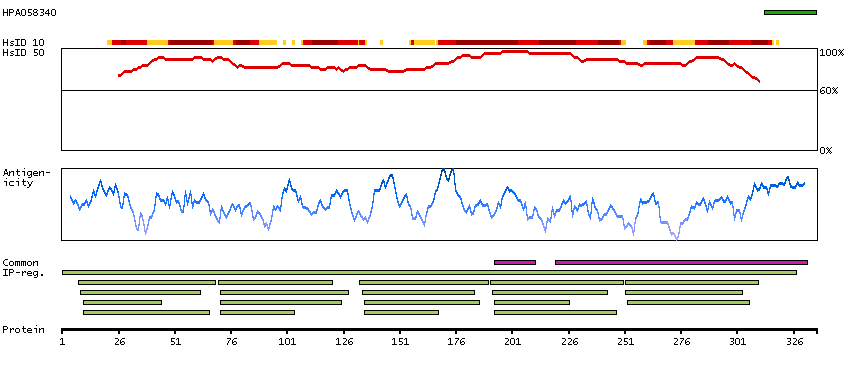
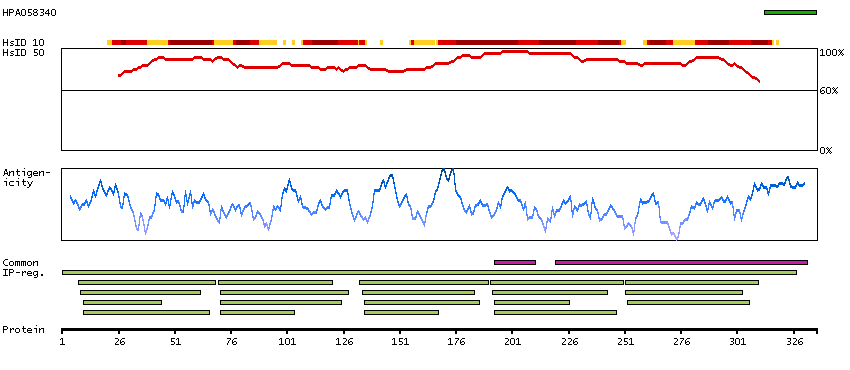
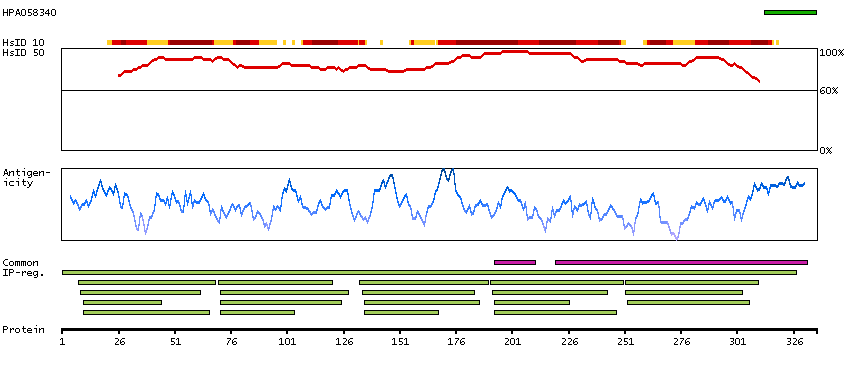
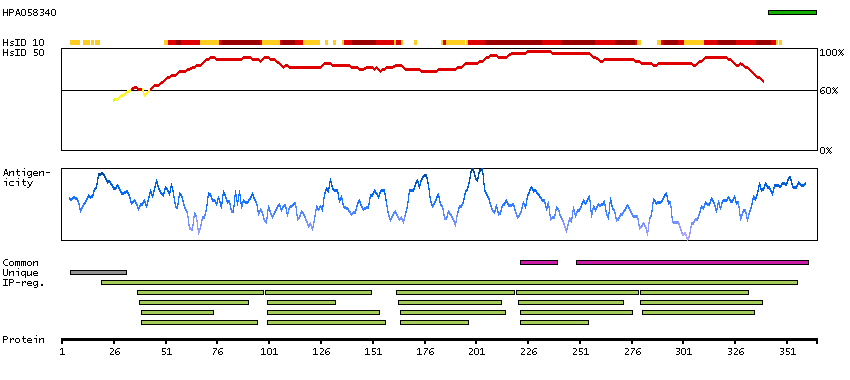
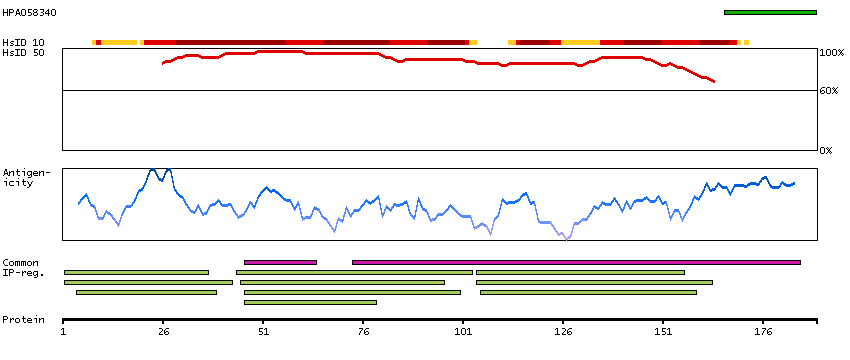
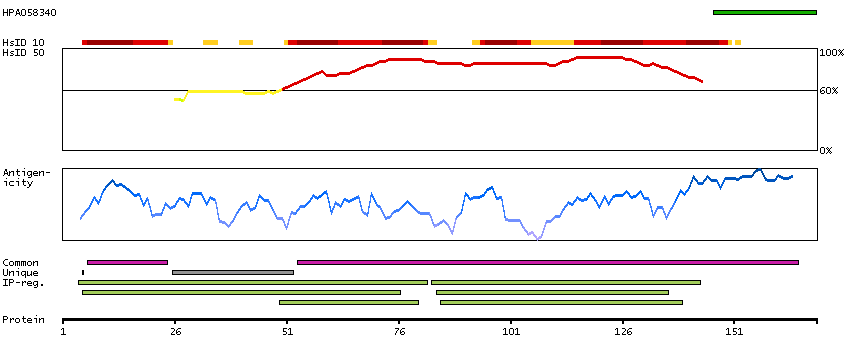
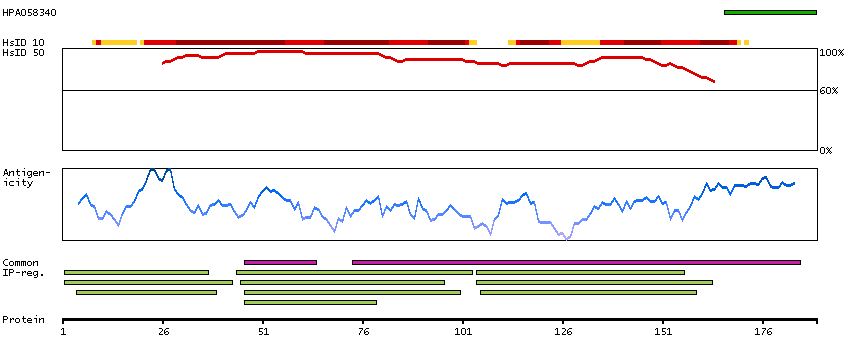
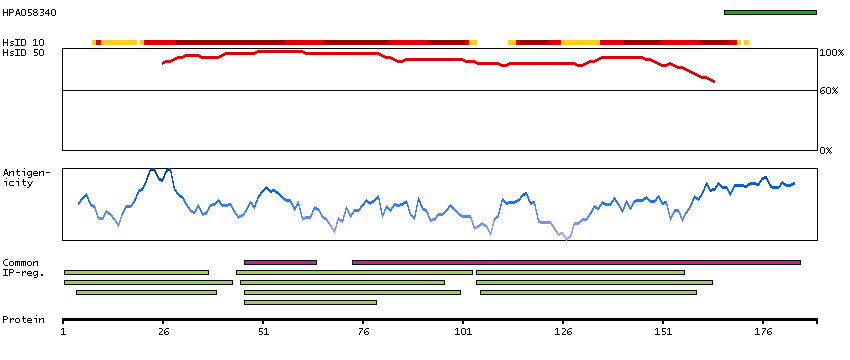
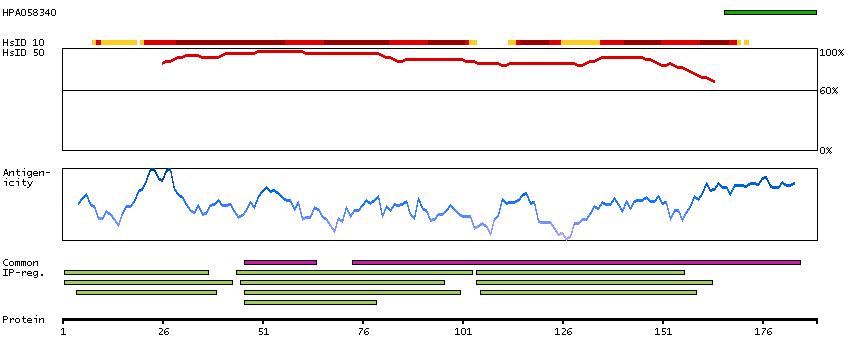
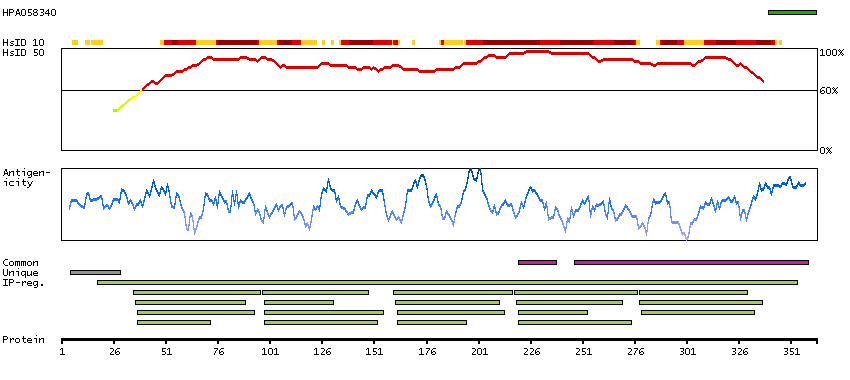
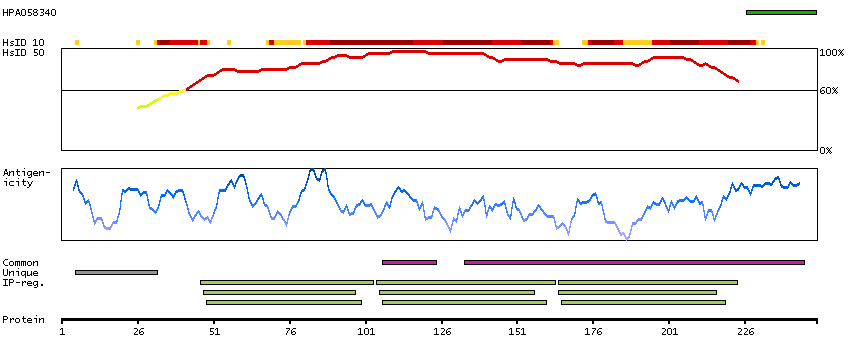
LIM and senescent cell antigen-like domains 2 (HGNC Symbol)
Entrez gene summary
This gene encodes a member of a small family of focal adhesion proteins which interacts with ILK (integrin-linked kinase), a protein which effects protein-protein interactions with the extraceullar matrix. The encoded protein has five LIM domains, each domain forming two zinc fingers, which permit interactions which regulate cell shape and migration. A pseudogene of this gene is located on chromosome 4. Multiple transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Nov 2011]