We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
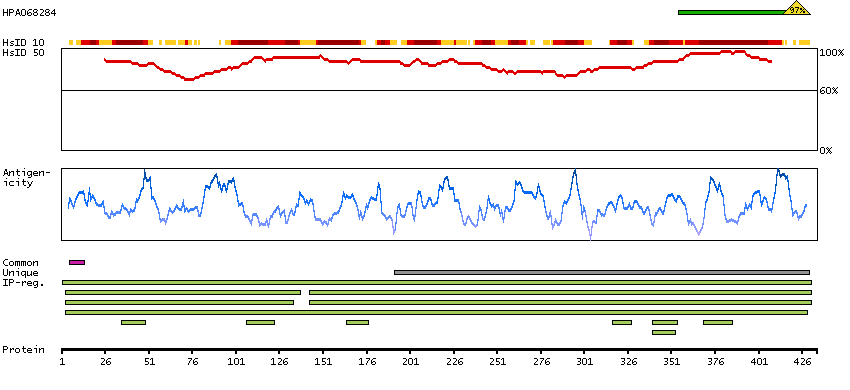
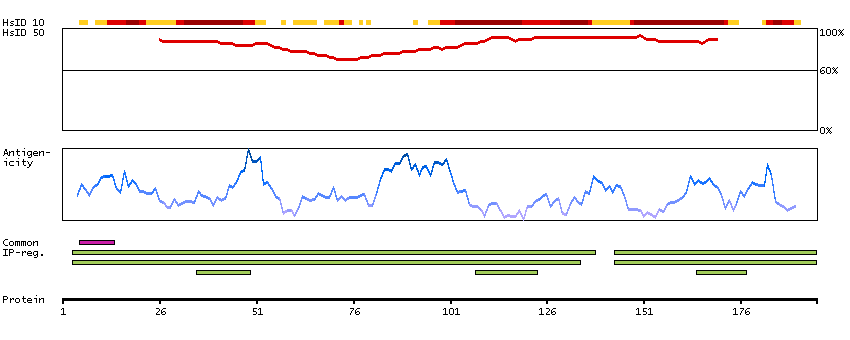
This gene encodes alpha-enolase, one of three enolase isoenzymes found in mammals. Each isoenzyme is a homodimer composed of 2 alpha, 2 gamma, or 2 beta subunits, and functions as a glycolytic enzyme. Alpha-enolase in addition, functions as a structural lens protein (tau-crystallin) in the monomeric form. Alternative splicing of this gene results in a shorter isoform that has been shown to bind to the c-myc promoter and function as a tumor suppressor. Several pseudogenes have been identified, including one on the long arm of chromosome 1. Alpha-enolase has also been identified as an autoantigen in Hashimoto encephalopathy. [provided by RefSeq, Jan 2011]
Enzymes ENZYME proteins Lyases SPOCTOPUS predicted membrane proteins Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)