We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
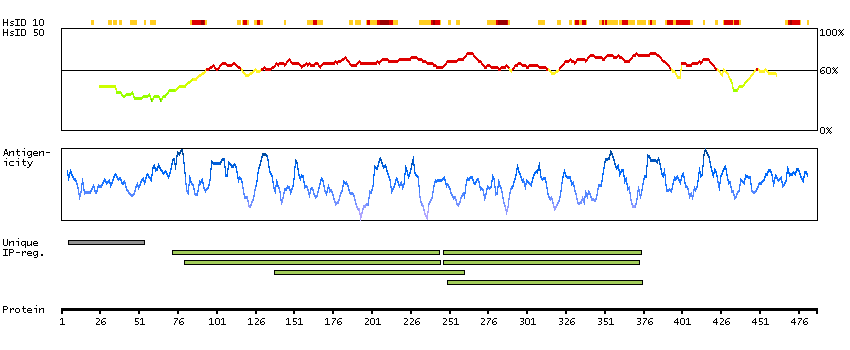
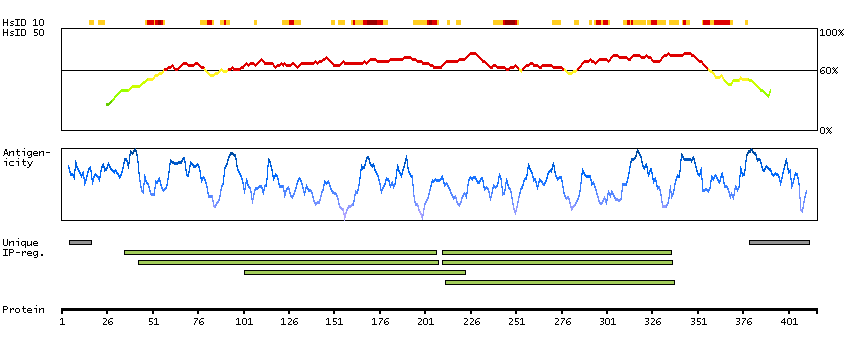
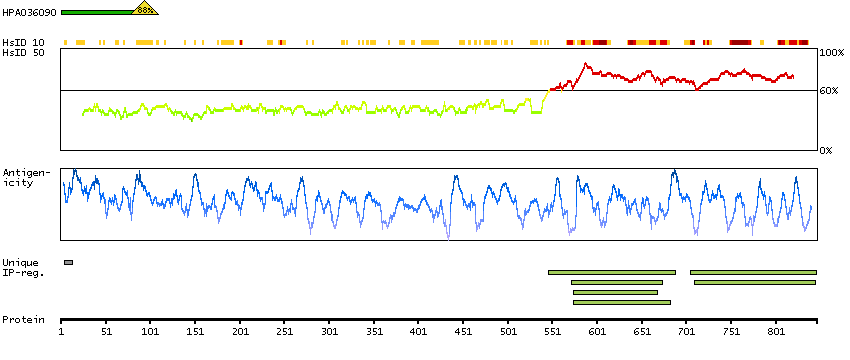
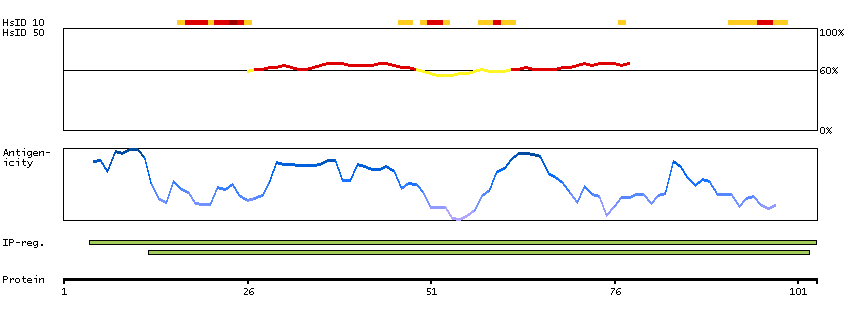
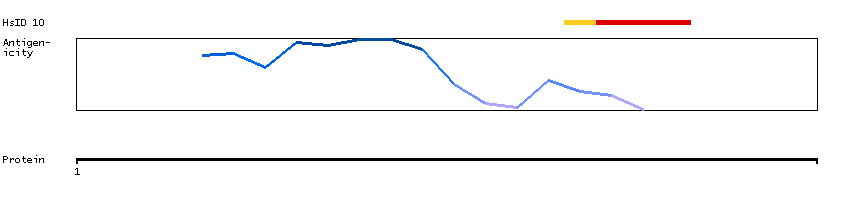
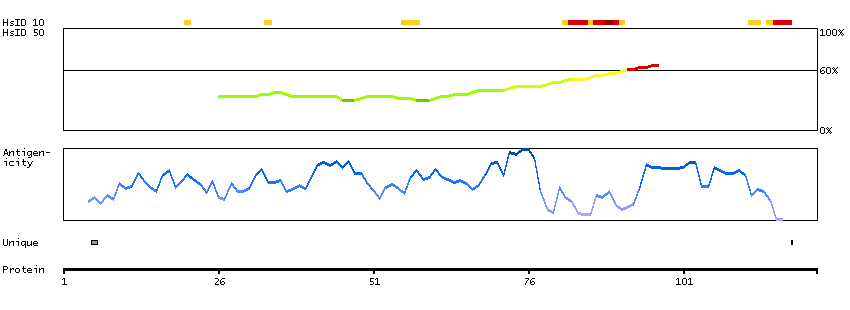
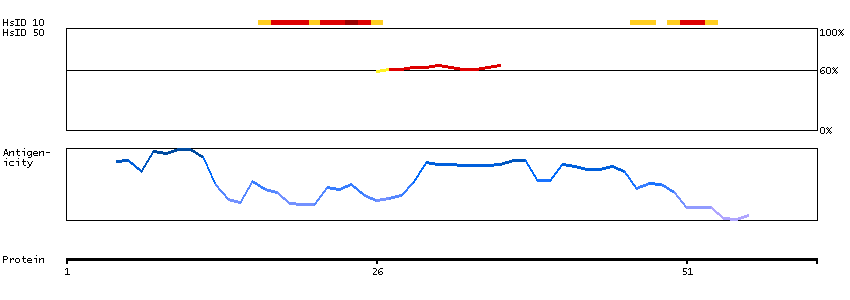
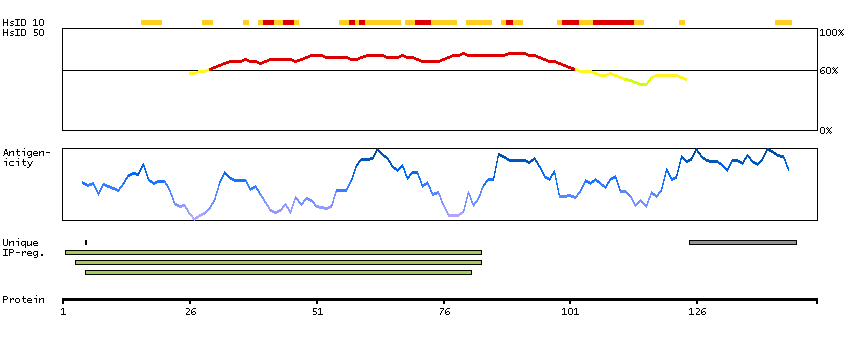
The protein encoded by this gene localizes to focal adhesions, regions of the plasma membrane where the cell attaches to the extracellular matrix. This protein crosslinks actin filaments and contains a Src homology 2 (SH2) domain, which is often found in molecules involved in signal transduction. This protein is a substrate of calpain II. Alternative splicing results in multiple transcript variants encoding different isoforms. [provided by RefSeq, Apr 2015]
SPOCTOPUS predicted membrane proteins Predicted intracellular proteins Plasma proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)