We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
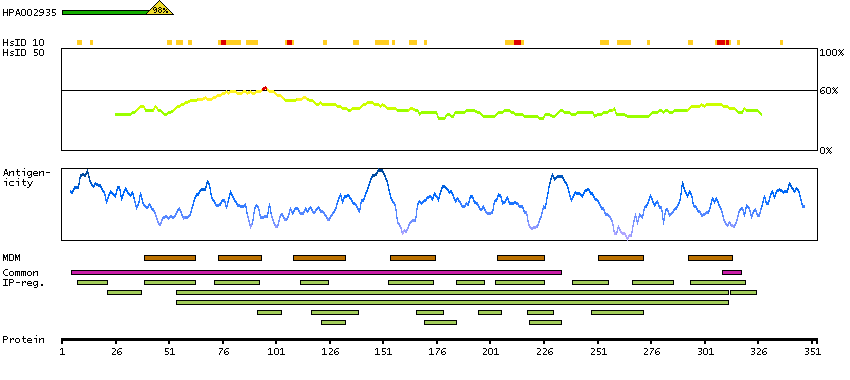
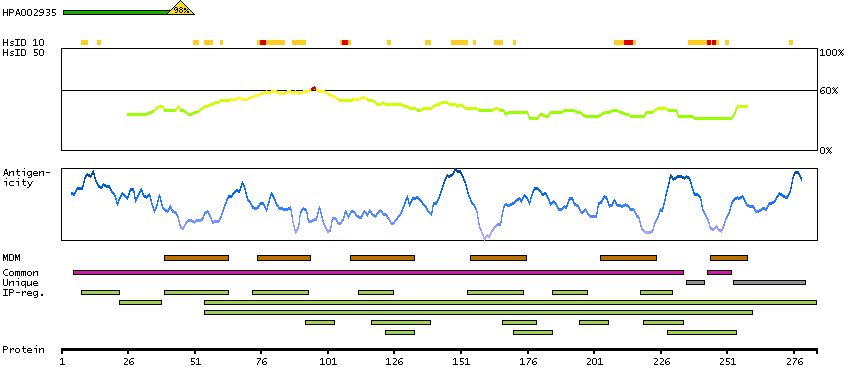
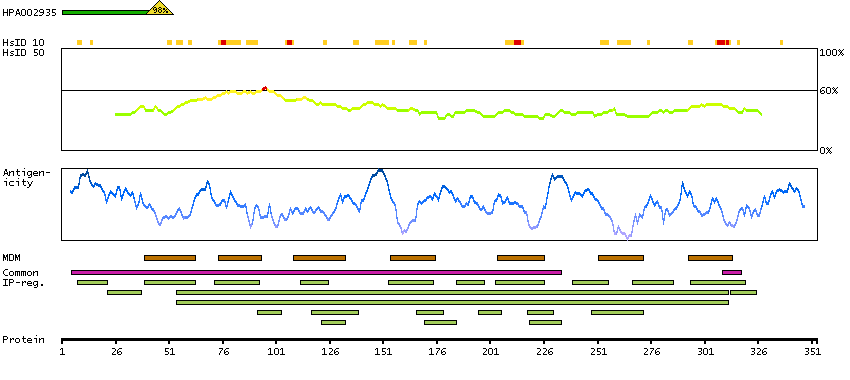
Bradykinin, a 9 aa peptide, is generated in pathophysiologic conditions such as inflammation, trauma, burns, shock, and allergy. Two types of G-protein coupled receptors have been found which bind bradykinin and mediate responses to these pathophysiologic conditions. The protein encoded by this gene is one of these receptors and is synthesized de novo following tissue injury. Receptor binding leads to an increase in the cytosolic calcium ion concentration, ultimately resulting in chronic and acute inflammatory responses. Several transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Sep 2011]