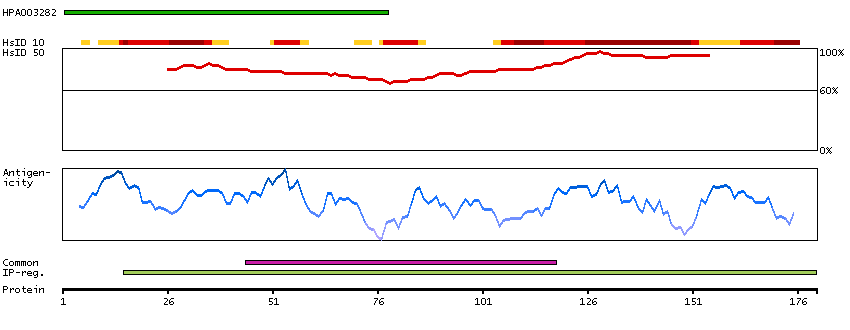
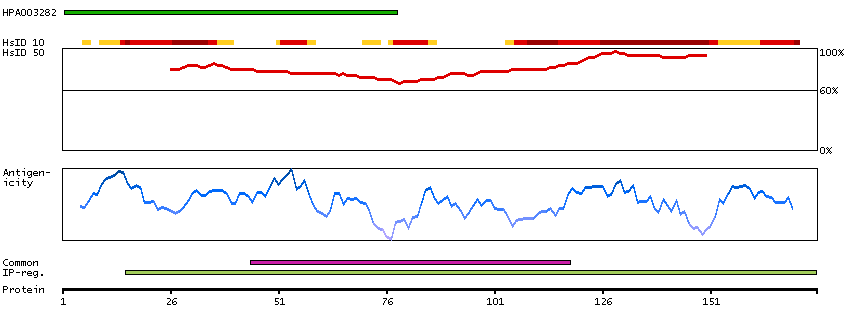
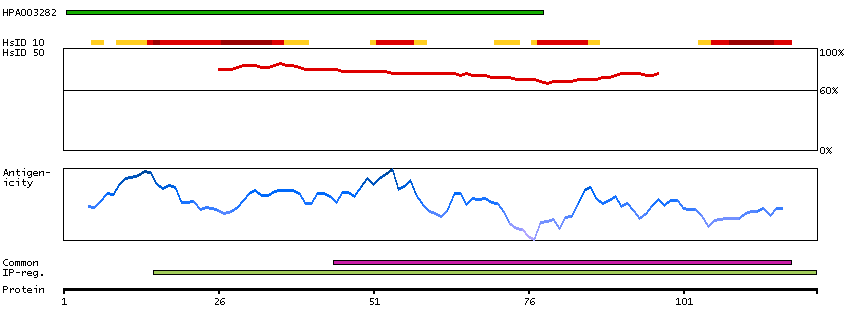
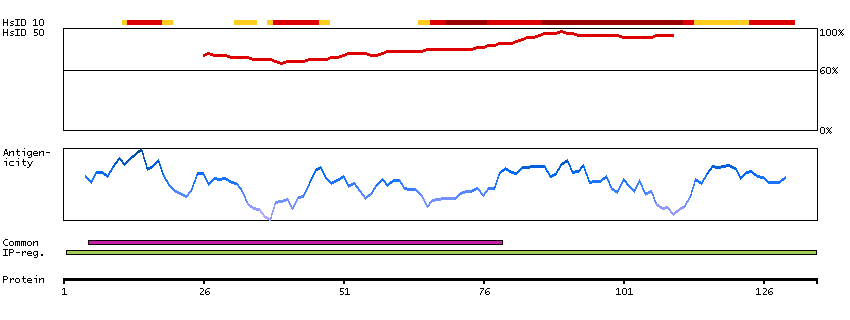
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
RNA tissue category: Group enriched (brain, caudate, cerebellum, hippocampus, retina)
GENE INFORMATION
Gene name
ALDOC
Synonyms
Description
Aldolase C, fructose-bisphosphate (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the class I fructose-biphosphate aldolase gene family. Expressed specifically in the hippocampus and Purkinje cells of the brain, the encoded protein is a glycolytic enzyme that catalyzes the reversible aldol cleavage of fructose-1,6-biphosphate and fructose 1-phosphate to dihydroxyacetone phosphate and either glyceraldehyde-3-phosphate or glyceraldehyde, respectively. [provided by RefSeq, Jul 2008]
Enzymes ENZYME proteins Lyases Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Candidate cardiovascular disease genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)