We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
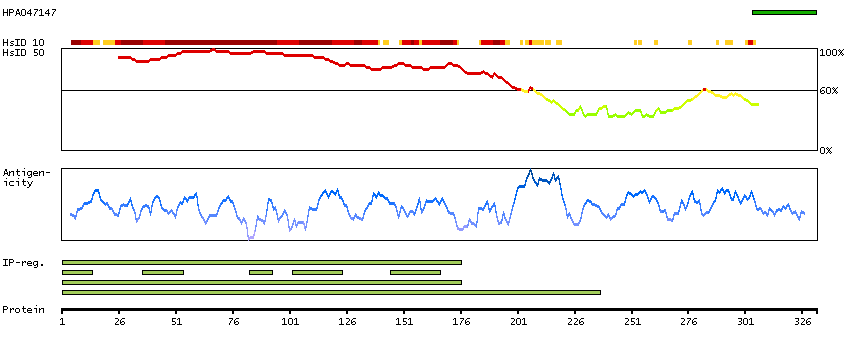
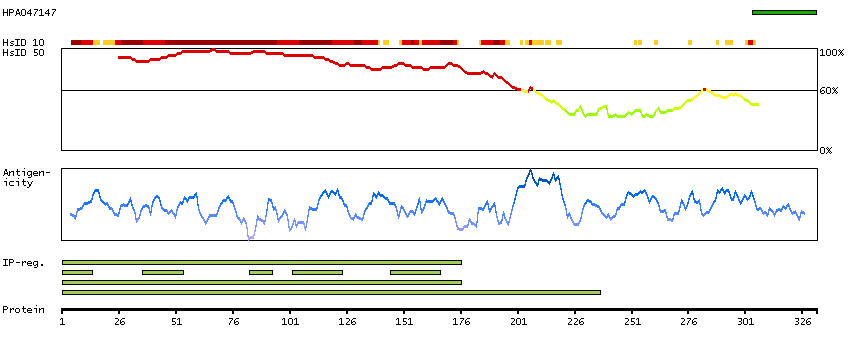
RNA-based expert annotation could not be performed, due to inconclusive results. View immunohistochemistry primary data.
RNA EXPRESSION OVERVIEW
HPA dataset
Organ
Expression
Alphabetical
RNA tissue category: Expressed in all
GTEx dataset
Organ
Expression
Alphabetical
RNA tissue category: Expressed in all
FANTOM5 dataset
Organ
Expression
Alphabetical
RNA tissue category: Expressed in all
GENE INFORMATION
Gene name
STK25 (HGNC Symbol)
Synonyms
SOK1, YSK1
Description
Serine/threonine kinase 25 (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the germinal centre kinase III (GCK III) subfamily of the sterile 20 superfamily of kinases. The encoded enzyme plays a role in serine-threonine liver kinase B1 (LKB1) signaling pathway to regulate neuronal polarization and morphology of the Golgi apparatus. The protein is translocated from the Golgi apparatus to the nucleus in response to chemical anoxia and plays a role in regulation of cell death. A pseudogene associated with this gene is located on chromosome 18. Multiple alternatively spliced transcript variants have been observed for this gene. [provided by RefSeq, Dec 2012]
Enzymes ENZYME proteins Transferases Kinases STE Ser/Thr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000139 [Golgi membrane] GO:0004672 [protein kinase activity] GO:0004674 [protein serine/threonine kinase activity] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005737 [cytoplasm] GO:0005794 [Golgi apparatus] GO:0006468 [protein phosphorylation] GO:0006979 [response to oxidative stress] GO:0007163 [establishment or maintenance of cell polarity] GO:0007165 [signal transduction] GO:0007346 [regulation of mitotic cell cycle] GO:0023014 [signal transduction by protein phosphorylation] GO:0031098 [stress-activated protein kinase signaling cascade] GO:0032147 [activation of protein kinase activity] GO:0032874 [positive regulation of stress-activated MAPK cascade] GO:0036481 [intrinsic apoptotic signaling pathway in response to hydrogen peroxide] GO:0042542 [response to hydrogen peroxide] GO:0042803 [protein homodimerization activity] GO:0042981 [regulation of apoptotic process] GO:0046777 [protein autophosphorylation] GO:0046872 [metal ion binding] GO:0050772 [positive regulation of axonogenesis] GO:0051645 [Golgi localization] GO:0051683 [establishment of Golgi localization] GO:0070062 [extracellular exosome] GO:0090168 [Golgi reassembly]
Enzymes ENZYME proteins Transferases Kinases STE Ser/Thr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004674 [protein serine/threonine kinase activity] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005737 [cytoplasm] GO:0005794 [Golgi apparatus] GO:0006468 [protein phosphorylation] GO:0006979 [response to oxidative stress] GO:0007165 [signal transduction] GO:0007346 [regulation of mitotic cell cycle] GO:0023014 [signal transduction by protein phosphorylation] GO:0031098 [stress-activated protein kinase signaling cascade] GO:0032147 [activation of protein kinase activity] GO:0032874 [positive regulation of stress-activated MAPK cascade] GO:0036481 [intrinsic apoptotic signaling pathway in response to hydrogen peroxide] GO:0042542 [response to hydrogen peroxide] GO:0042803 [protein homodimerization activity] GO:0042981 [regulation of apoptotic process] GO:0046777 [protein autophosphorylation] GO:0046872 [metal ion binding] GO:0051645 [Golgi localization] GO:0051683 [establishment of Golgi localization] GO:0070062 [extracellular exosome] GO:0090168 [Golgi reassembly]
Enzymes ENZYME proteins Transferases Kinases STE Ser/Thr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004674 [protein serine/threonine kinase activity] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005737 [cytoplasm] GO:0005794 [Golgi apparatus] GO:0006468 [protein phosphorylation] GO:0006979 [response to oxidative stress] GO:0007165 [signal transduction] GO:0007346 [regulation of mitotic cell cycle] GO:0023014 [signal transduction by protein phosphorylation] GO:0031098 [stress-activated protein kinase signaling cascade] GO:0032147 [activation of protein kinase activity] GO:0032874 [positive regulation of stress-activated MAPK cascade] GO:0036481 [intrinsic apoptotic signaling pathway in response to hydrogen peroxide] GO:0042542 [response to hydrogen peroxide] GO:0042803 [protein homodimerization activity] GO:0042981 [regulation of apoptotic process] GO:0046777 [protein autophosphorylation] GO:0046872 [metal ion binding] GO:0051645 [Golgi localization] GO:0051683 [establishment of Golgi localization] GO:0070062 [extracellular exosome] GO:0090168 [Golgi reassembly]
Enzymes ENZYME proteins Transferases Kinases STE Ser/Thr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004674 [protein serine/threonine kinase activity] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005737 [cytoplasm] GO:0005794 [Golgi apparatus] GO:0006468 [protein phosphorylation] GO:0006979 [response to oxidative stress] GO:0007165 [signal transduction] GO:0007346 [regulation of mitotic cell cycle] GO:0023014 [signal transduction by protein phosphorylation] GO:0031098 [stress-activated protein kinase signaling cascade] GO:0032147 [activation of protein kinase activity] GO:0032874 [positive regulation of stress-activated MAPK cascade] GO:0036481 [intrinsic apoptotic signaling pathway in response to hydrogen peroxide] GO:0042542 [response to hydrogen peroxide] GO:0042803 [protein homodimerization activity] GO:0042981 [regulation of apoptotic process] GO:0046777 [protein autophosphorylation] GO:0046872 [metal ion binding] GO:0051645 [Golgi localization] GO:0051683 [establishment of Golgi localization] GO:0070062 [extracellular exosome] GO:0090168 [Golgi reassembly]
Enzymes ENZYME proteins Transferases Kinases STE Ser/Thr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004674 [protein serine/threonine kinase activity] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005737 [cytoplasm] GO:0005794 [Golgi apparatus] GO:0006468 [protein phosphorylation] GO:0006979 [response to oxidative stress] GO:0007165 [signal transduction] GO:0007346 [regulation of mitotic cell cycle] GO:0023014 [signal transduction by protein phosphorylation] GO:0031098 [stress-activated protein kinase signaling cascade] GO:0032147 [activation of protein kinase activity] GO:0032874 [positive regulation of stress-activated MAPK cascade] GO:0036481 [intrinsic apoptotic signaling pathway in response to hydrogen peroxide] GO:0042542 [response to hydrogen peroxide] GO:0042803 [protein homodimerization activity] GO:0042981 [regulation of apoptotic process] GO:0046777 [protein autophosphorylation] GO:0046872 [metal ion binding] GO:0051645 [Golgi localization] GO:0051683 [establishment of Golgi localization] GO:0070062 [extracellular exosome] GO:0090168 [Golgi reassembly]
Enzymes ENZYME proteins Transferases Kinases STE Ser/Thr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004674 [protein serine/threonine kinase activity] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005737 [cytoplasm] GO:0005794 [Golgi apparatus] GO:0006468 [protein phosphorylation] GO:0006979 [response to oxidative stress] GO:0007165 [signal transduction] GO:0007346 [regulation of mitotic cell cycle] GO:0023014 [signal transduction by protein phosphorylation] GO:0031098 [stress-activated protein kinase signaling cascade] GO:0032147 [activation of protein kinase activity] GO:0032874 [positive regulation of stress-activated MAPK cascade] GO:0036481 [intrinsic apoptotic signaling pathway in response to hydrogen peroxide] GO:0042542 [response to hydrogen peroxide] GO:0042803 [protein homodimerization activity] GO:0042981 [regulation of apoptotic process] GO:0046777 [protein autophosphorylation] GO:0046872 [metal ion binding] GO:0051645 [Golgi localization] GO:0051683 [establishment of Golgi localization] GO:0070062 [extracellular exosome] GO:0090168 [Golgi reassembly]
Enzymes ENZYME proteins Transferases Kinases STE Ser/Thr protein kinases Predicted intracellular proteins Plasma proteins Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004674 [protein serine/threonine kinase activity] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005737 [cytoplasm] GO:0005794 [Golgi apparatus] GO:0006468 [protein phosphorylation] GO:0006979 [response to oxidative stress] GO:0007165 [signal transduction] GO:0007346 [regulation of mitotic cell cycle] GO:0023014 [signal transduction by protein phosphorylation] GO:0031098 [stress-activated protein kinase signaling cascade] GO:0032147 [activation of protein kinase activity] GO:0032874 [positive regulation of stress-activated MAPK cascade] GO:0036481 [intrinsic apoptotic signaling pathway in response to hydrogen peroxide] GO:0042542 [response to hydrogen peroxide] GO:0042803 [protein homodimerization activity] GO:0042981 [regulation of apoptotic process] GO:0046777 [protein autophosphorylation] GO:0046872 [metal ion binding] GO:0051645 [Golgi localization] GO:0051683 [establishment of Golgi localization] GO:0070062 [extracellular exosome] GO:0090168 [Golgi reassembly]