We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
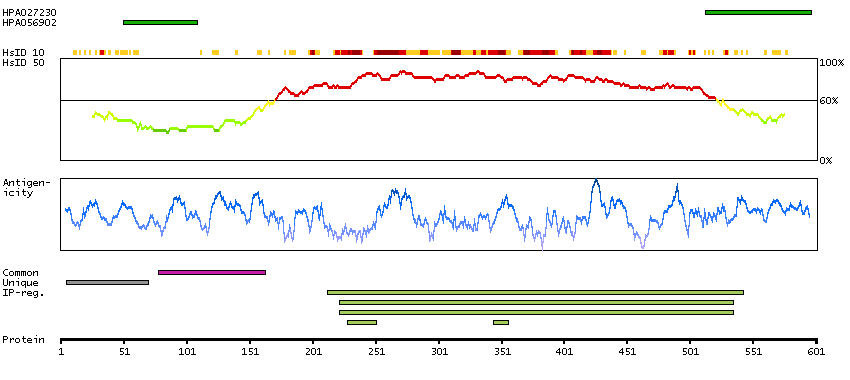
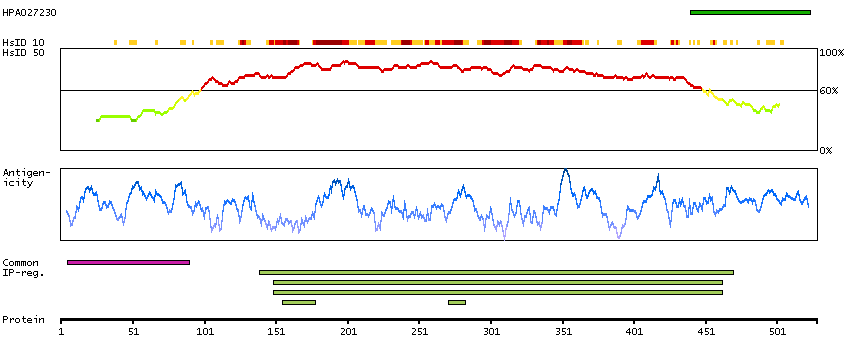
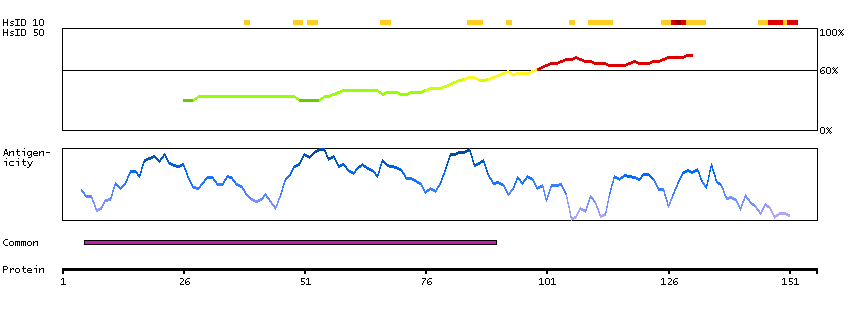
DYRK2 belongs to a family of protein kinases whose members are presumed to be involved in cellular growth and/or development. The family is defined by structural similarity of their kinase domains and their capability to autophosphorylate on tyrosine residues. DYRK2 has demonstrated tyrosine autophosphorylation and catalyzed phosphorylation of histones H3 and H2B in vitro. Two isoforms of DYRK2 have been isolated. The predominant isoform, isoform 1, lacks a 5' terminal insert. [provided by RefSeq, Jul 2008]