We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
The protein encoded by this gene catalyzes the penultimate step of the arginine biosynthetic pathway. There are approximately 10 to 14 copies of this gene including the pseudogenes scattered across the human genome, among which the one located on chromosome 9 appears to be the only functional gene for argininosuccinate synthetase. Mutations in the chromosome 9 copy of this gene cause citrullinemia. Two transcript variants encoding the same protein have been found for this gene. [provided by RefSeq, Aug 2012]
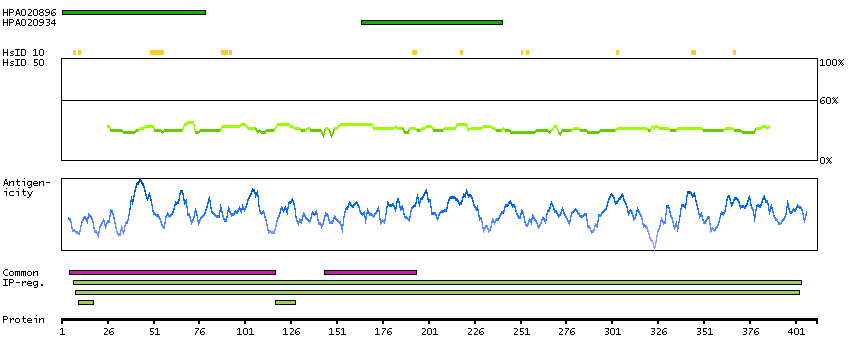
P00966 [Direct mapping] Argininosuccinate synthase Q5T6L4 [Target identity:100%; Query identity:100%] Argininosuccinate synthetase, isoform CRA_a; cDNA, FLJ96050, highly similar to Homo sapiens argininosuccinate synthetase (ASS), transcript variant1, mRNA
Show all
Enzymes ENZYME proteins Ligase Predicted intracellular proteins Plasma proteins Disease related genes Potential drug targets Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
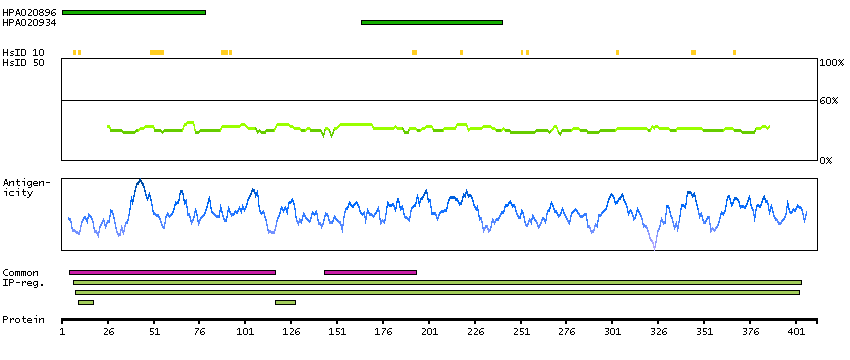
P00966 [Direct mapping] Argininosuccinate synthase Q5T6L4 [Target identity:100%; Query identity:100%] Argininosuccinate synthetase, isoform CRA_a; cDNA, FLJ96050, highly similar to Homo sapiens argininosuccinate synthetase (ASS), transcript variant1, mRNA
Show all
Enzymes ENZYME proteins Ligase Predicted intracellular proteins Plasma proteins Disease related genes Potential drug targets Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
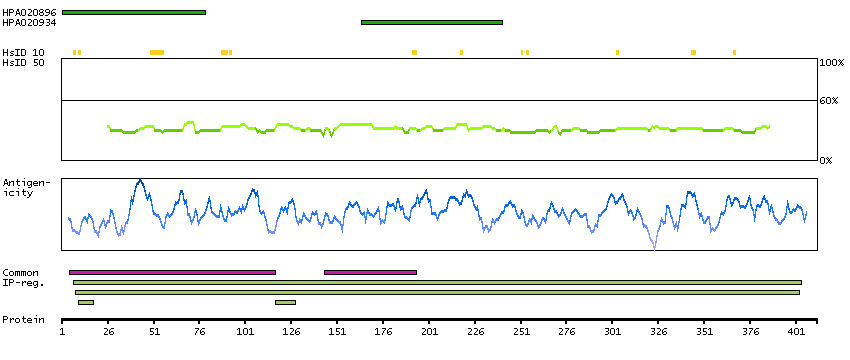
P00966 [Direct mapping] Argininosuccinate synthase Q5T6L4 [Target identity:100%; Query identity:100%] Argininosuccinate synthetase, isoform CRA_a; cDNA, FLJ96050, highly similar to Homo sapiens argininosuccinate synthetase (ASS), transcript variant1, mRNA
Show all
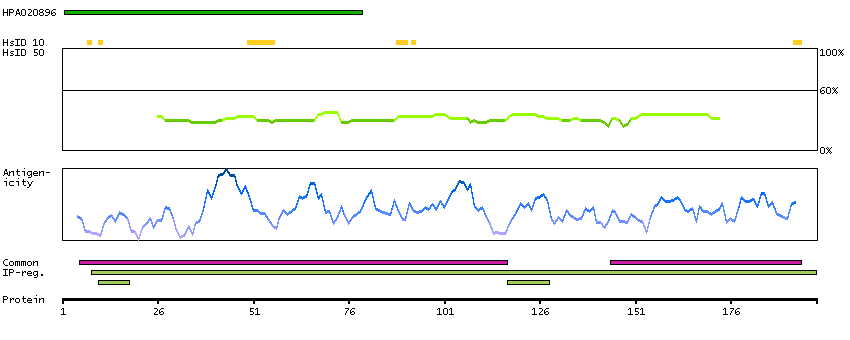
Enzymes ENZYME proteins Ligase Predicted intracellular proteins Plasma proteins Disease related genes Potential drug targets Protein evidence (Ezkurdia et al 2014)