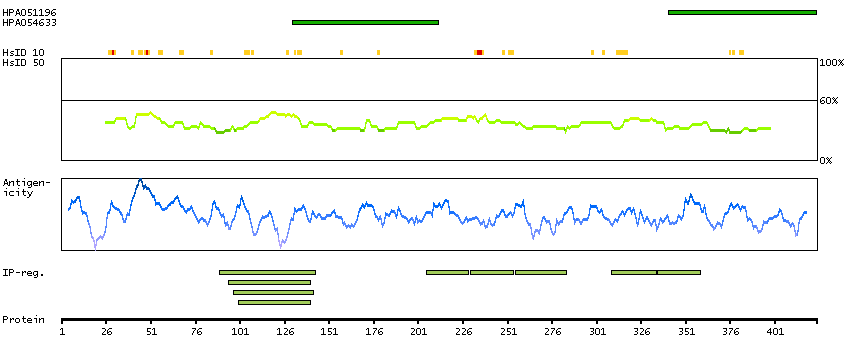
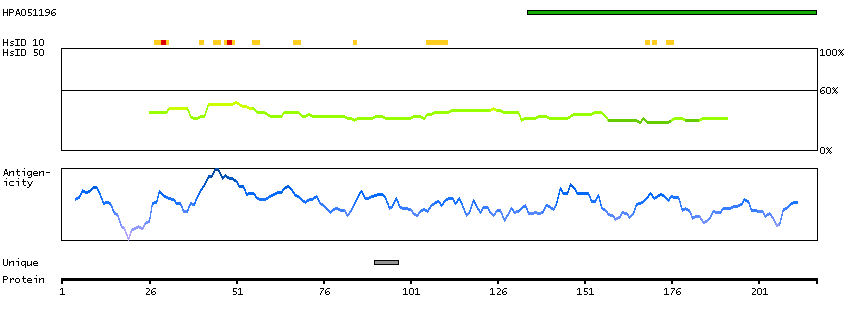
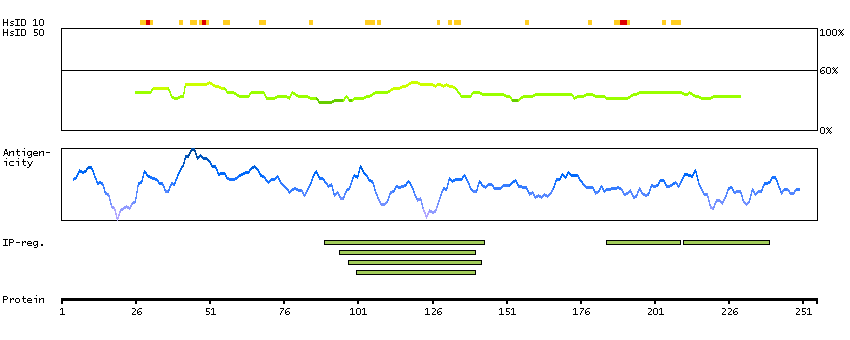
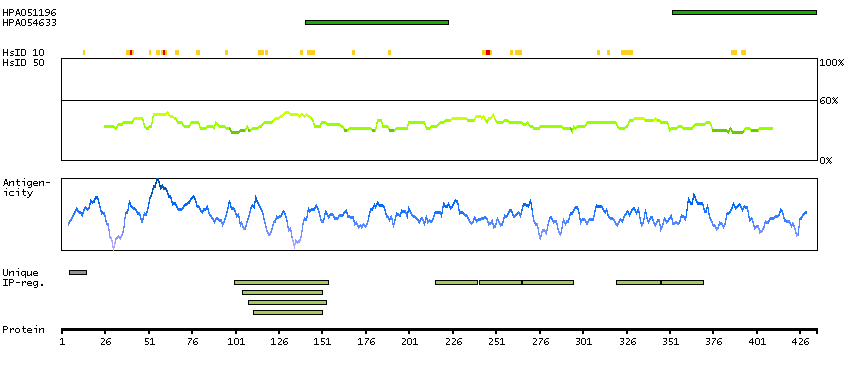
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
S-phase kinase-associated protein 2, E3 ubiquitin protein ligase (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the F-box protein family which is characterized by an approximately 40 amino acid motif, the F-box. The F-box proteins constitute one of the four subunits of ubiquitin protein ligase complex called SCFs (SKP1-cullin-F-box), which function in phosphorylation-dependent ubiquitination. The F-box proteins are divided into 3 classes: Fbws containing WD-40 domains, Fbls containing leucine-rich repeats, and Fbxs containing either different protein-protein interaction modules or no recognizable motifs. The protein encoded by this gene belongs to the Fbls class; in addition to an F-box, this protein contains 10 tandem leucine-rich repeats. This protein is an essential element of the cyclin A-CDK2 S-phase kinase. It specifically recognizes phosphorylated cyclin-dependent kinase inhibitor 1B (CDKN1B, also referred to as p27 or KIP1) predominantly in S phase and interacts with S-phase kinase-associated protein 1 (SKP1 or p19). In addition, this gene is established as a protooncogene causally involved in the pathogenesis of lymphomas. Alternative splicing of this gene generates three transcript variants encoding different isoforms. [provided by RefSeq, Jul 2011]
Q13309 [Direct mapping] S-phase kinase-associated protein 2
Show all
Phobius predicted membrane proteins Predicted intracellular proteins Cancer-related genes Candidate cancer biomarkers Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Q13309 [Direct mapping] S-phase kinase-associated protein 2 A0A024R069 [Target identity:100%; Query identity:100%] S-phase kinase-associated protein 2 (P45), isoform CRA_c
Show all
Predicted intracellular proteins Cancer-related genes Candidate cancer biomarkers Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000082 [G1/S transition of mitotic cell cycle] GO:0000086 [G2/M transition of mitotic cell cycle] GO:0000209 [protein polyubiquitination] GO:0000278 [mitotic cell cycle] GO:0005515 [protein binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005730 [nucleolus] GO:0005737 [cytoplasm] GO:0005829 [cytosol] GO:0006511 [ubiquitin-dependent protein catabolic process] GO:0008283 [cell proliferation] GO:0016235 [aggresome] GO:0016567 [protein ubiquitination] GO:0019005 [SCF ubiquitin ligase complex] GO:0031145 [anaphase-promoting complex-dependent proteasomal ubiquitin-dependent protein catabolic process] GO:0031146 [SCF-dependent proteasomal ubiquitin-dependent protein catabolic process] GO:0033148 [positive regulation of intracellular estrogen receptor signaling pathway] GO:0042802 [identical protein binding] GO:0042981 [regulation of apoptotic process] GO:0048661 [positive regulation of smooth muscle cell proliferation] GO:0051726 [regulation of cell cycle] GO:0061630 [ubiquitin protein ligase activity] GO:0071460 [cellular response to cell-matrix adhesion] GO:1902916 [positive regulation of protein polyubiquitination]