We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Nuclear factor of kappa light polypeptide gene enhancer in B-cells inhibitor, epsilon (HGNC Symbol)
Entrez gene summary
The protein encoded by this gene binds to components of NF-kappa-B, trapping the complex in the cytoplasm and preventing it from activating genes in the nucleus. Phosphorylation of the encoded protein targets it for destruction by the ubiquitin pathway, which activates NF-kappa-B by making it available to translocate to the nucleus. [provided by RefSeq, Sep 2011]
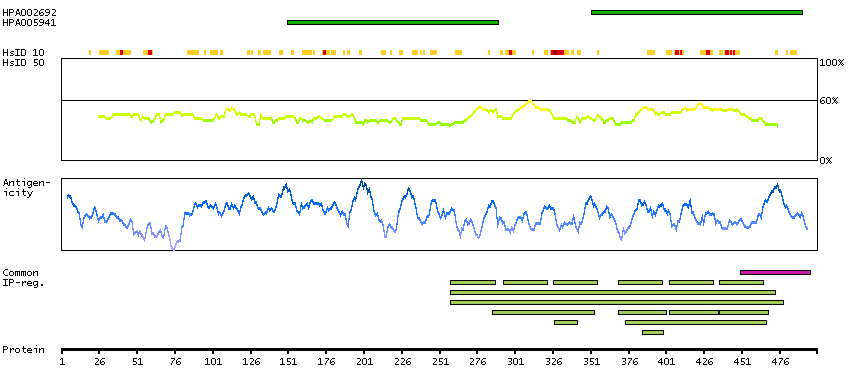
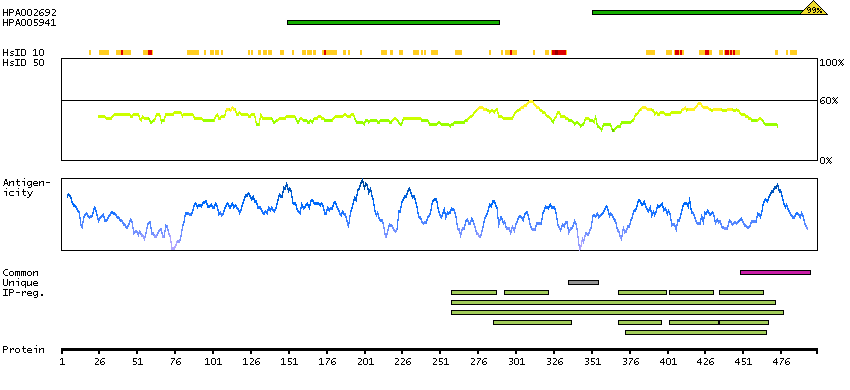
THUMBUP predicted membrane proteins Predicted intracellular proteins Transcription factors Immunoglobulin fold Cancer-related genes Candidate cancer biomarkers COSMIC somatic mutations in cancer genes COSMIC Somatic Mutations COSMIC Frameshift Mutations Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
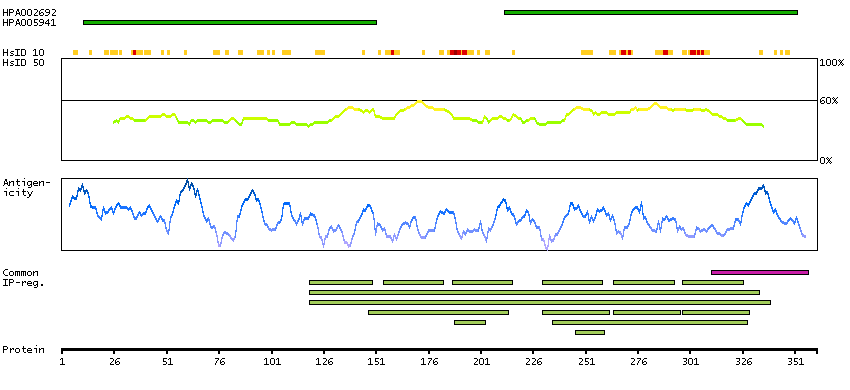
Predicted intracellular proteins Cancer-related genes COSMIC somatic mutations in cancer genes COSMIC Somatic Mutations COSMIC Frameshift Mutations Protein evidence (Ezkurdia et al 2014)