We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Expression in the nuclei and nuclear membranes in most cells, highly expressed in subsets of cells in the gastrointestinal tract, immune cells and basal epithelial cells.
DATA RELIABILITY
Data reliability description
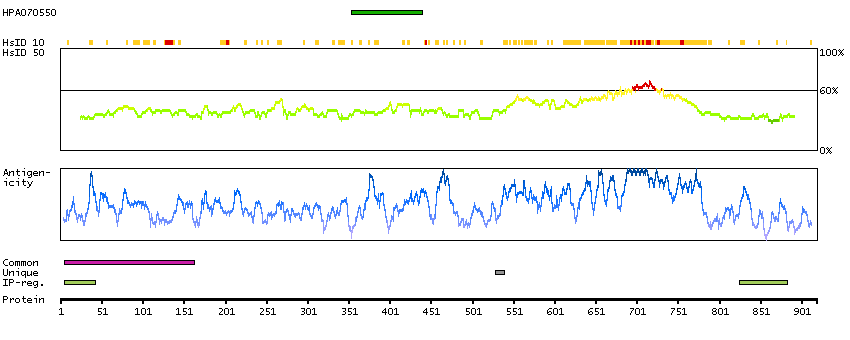
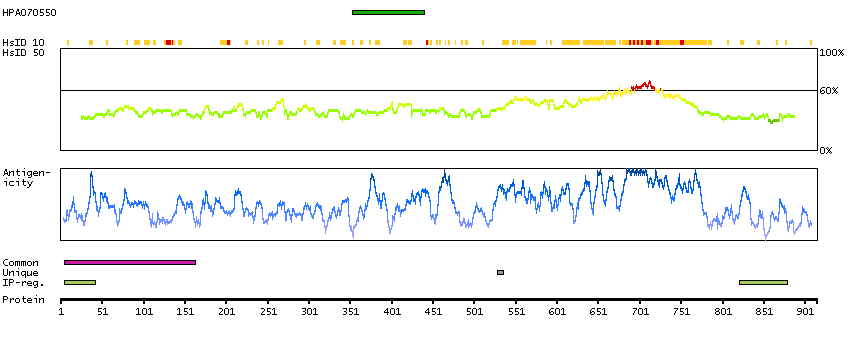
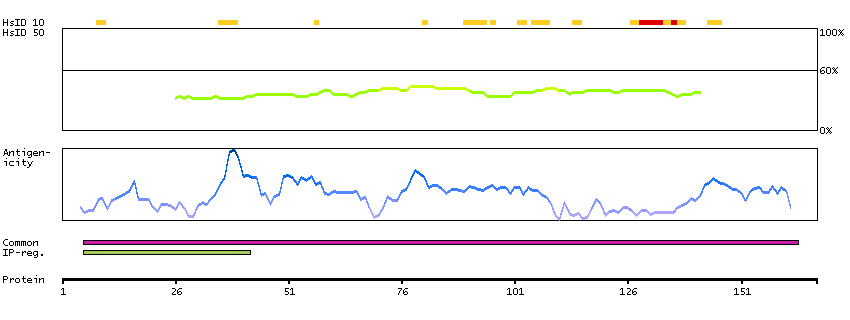
Antibody staining mainly consistent with RNA expression data.
Inner centromere protein antigens 135/155kDa (HGNC Symbol)
Entrez gene summary
In mammalian cells, 2 broad groups of centromere-interacting proteins have been described: constitutively binding centromere proteins and 'passenger,' or transiently interacting, proteins (reviewed by Choo, 1997). The constitutive proteins include CENPA (centromere protein A; MIM 117139), CENPB (MIM 117140), CENPC1 (MIM 117141), and CENPD (MIM 117142). The term 'passenger proteins' encompasses a broad collection of proteins that localize to the centromere during specific stages of the cell cycle (Earnshaw and Mackay, 1994 [PubMed 8088460]). These include CENPE (MIM 117143); MCAK (MIM 604538); KID (MIM 603213); cytoplasmic dynein (e.g., MIM 600112); CliPs (e.g., MIM 179838); and CENPF/mitosin (MIM 600236). The inner centromere proteins (INCENPs) (Earnshaw and Cooke, 1991 [PubMed 1860899]), the initial members of the passenger protein group, display a broad localization along chromosomes in the early stages of mitosis but gradually become concentrated at centromeres as the cell cycle progresses into mid-metaphase. During telophase, the proteins are located within the midbody in the intercellular bridge, where they are discarded after cytokinesis (Cutts et al., 1999 [PubMed 10369859]).[supplied by OMIM, Mar 2008]