We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
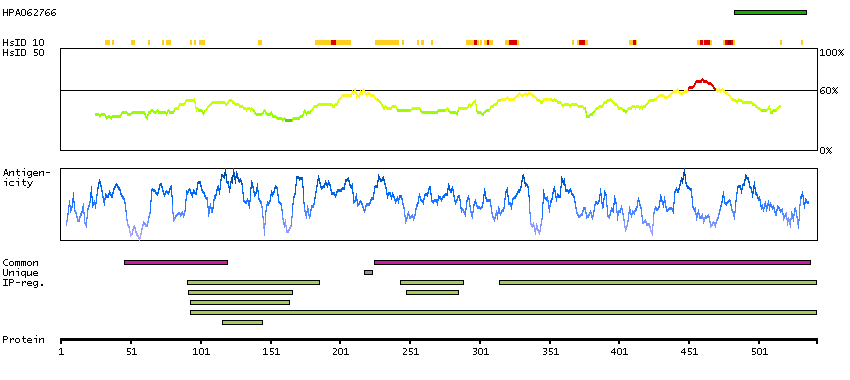
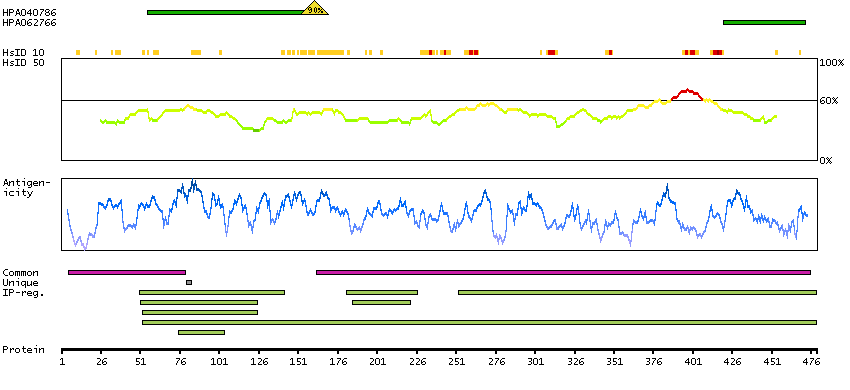
This gene encodes component E2 of the multi-enzyme pyruvate dehydrogenase complex (PDC). PDC resides in the inner mitochondrial membrane and catalyzes the conversion of pyruvate to acetyl coenzyme A. The protein product of this gene, dihydrolipoamide acetyltransferase, accepts acetyl groups formed by the oxidative decarboxylation of pyruvate and transfers them to coenzyme A. Dihydrolipoamide acetyltransferase is the antigen for antimitochondrial antibodies. These autoantibodies are present in nearly 95% of patients with the autoimmune liver disease primary biliary cirrhosis (PBC). In PBC, activated T lymphocytes attack and destroy epithelial cells in the bile duct where this protein is abnormally distributed and overexpressed. PBC enventually leads to cirrhosis and liver failure. Mutations in this gene are also a cause of pyruvate dehydrogenase E2 deficiency which causes primary lactic acidosis in infancy and early childhood.[provided by RefSeq, Oct 2009]
Enzymes ENZYME proteins Transferases MEMSAT3 predicted membrane proteins Predicted intracellular proteins Citric acid cycle related proteins Disease related genes Potential drug targets Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)