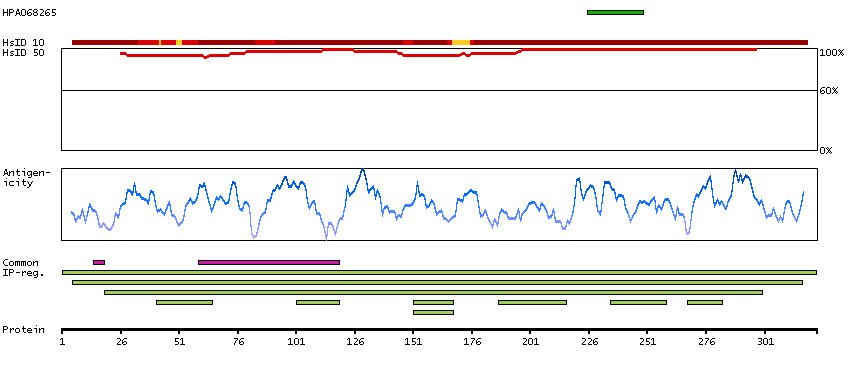
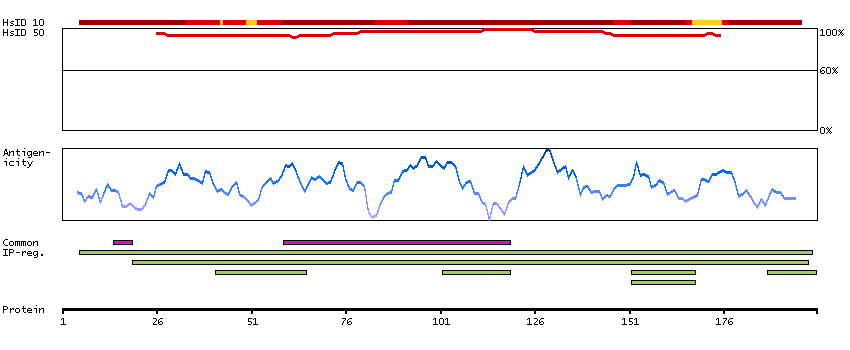
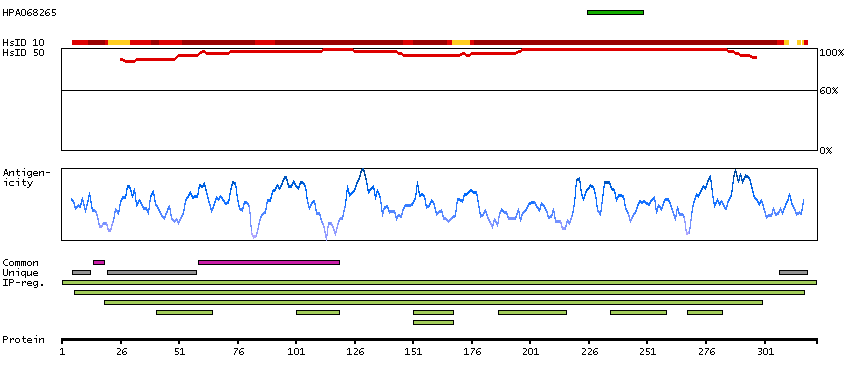
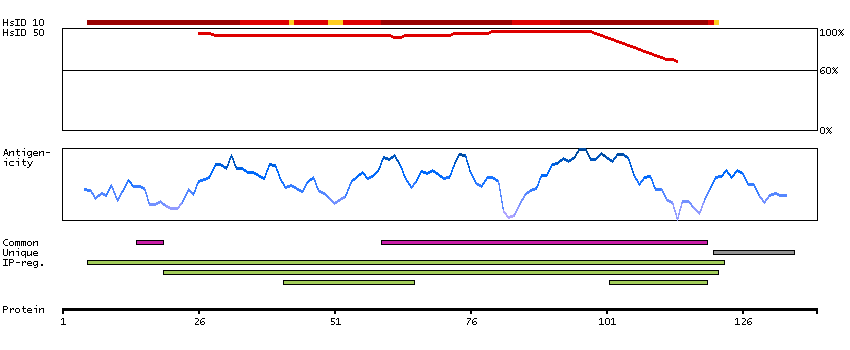
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Aldo-keto reductase family 1, member C2 (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the aldo/keto reductase superfamily, which consists of more than 40 known enzymes and proteins. These enzymes catalyze the conversion of aldehydes and ketones to their corresponding alcohols using NADH and/or NADPH as cofactors. The enzymes display overlapping but distinct substrate specificity. This enzyme binds bile acid with high affinity, and shows minimal 3-alpha-hydroxysteroid dehydrogenase activity. This gene shares high sequence identity with three other gene members and is clustered with those three genes at chromosome 10p15-p14. Three transcript variants encoding two different isoforms have been found for this gene. [provided by RefSeq, Dec 2011]
P52895 [Direct mapping] Aldo-keto reductase family 1 member C2
Show all
Enzymes ENZYME proteins Oxidoreductases Predicted intracellular proteins Disease related genes FDA approved drug targets Small molecule drugs Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004032 [alditol:NADP+ 1-oxidoreductase activity] GO:0005737 [cytoplasm] GO:0006693 [prostaglandin metabolic process] GO:0007186 [G-protein coupled receptor signaling pathway] GO:0007586 [digestion] GO:0008202 [steroid metabolic process] GO:0008284 [positive regulation of cell proliferation] GO:0016491 [oxidoreductase activity] GO:0016655 [oxidoreductase activity, acting on NAD(P)H, quinone or similar compound as acceptor] GO:0018636 [phenanthrene 9,10-monooxygenase activity] GO:0030855 [epithelial cell differentiation] GO:0031406 [carboxylic acid binding] GO:0032052 [bile acid binding] GO:0042448 [progesterone metabolic process] GO:0044597 [daunorubicin metabolic process] GO:0044598 [doxorubicin metabolic process] GO:0047086 [ketosteroid monooxygenase activity] GO:0047115 [trans-1,2-dihydrobenzene-1,2-diol dehydrogenase activity] GO:0051897 [positive regulation of protein kinase B signaling] GO:0055114 [oxidation-reduction process] GO:0071395 [cellular response to jasmonic acid stimulus] GO:0071799 [cellular response to prostaglandin D stimulus]
P52895 [Direct mapping] Aldo-keto reductase family 1 member C2
Show all
Enzymes ENZYME proteins Oxidoreductases Predicted intracellular proteins Disease related genes FDA approved drug targets Small molecule drugs Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004032 [alditol:NADP+ 1-oxidoreductase activity] GO:0005737 [cytoplasm] GO:0006693 [prostaglandin metabolic process] GO:0007186 [G-protein coupled receptor signaling pathway] GO:0007586 [digestion] GO:0008202 [steroid metabolic process] GO:0008284 [positive regulation of cell proliferation] GO:0016655 [oxidoreductase activity, acting on NAD(P)H, quinone or similar compound as acceptor] GO:0018636 [phenanthrene 9,10-monooxygenase activity] GO:0030855 [epithelial cell differentiation] GO:0031406 [carboxylic acid binding] GO:0032052 [bile acid binding] GO:0042448 [progesterone metabolic process] GO:0044597 [daunorubicin metabolic process] GO:0044598 [doxorubicin metabolic process] GO:0047086 [ketosteroid monooxygenase activity] GO:0047115 [trans-1,2-dihydrobenzene-1,2-diol dehydrogenase activity] GO:0051897 [positive regulation of protein kinase B signaling] GO:0055114 [oxidation-reduction process] GO:0071395 [cellular response to jasmonic acid stimulus] GO:0071799 [cellular response to prostaglandin D stimulus]