We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
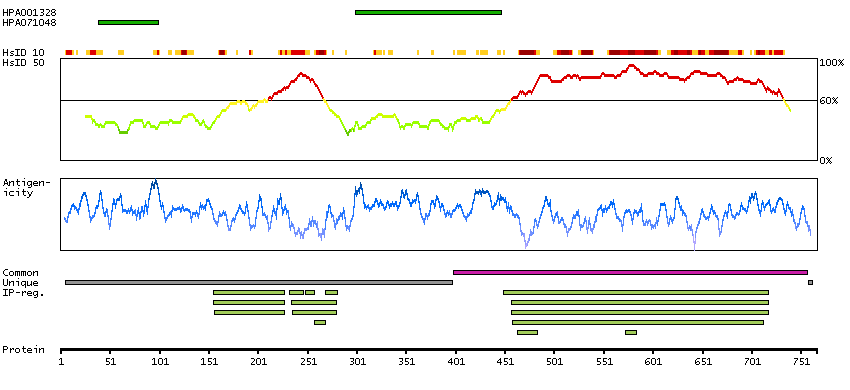
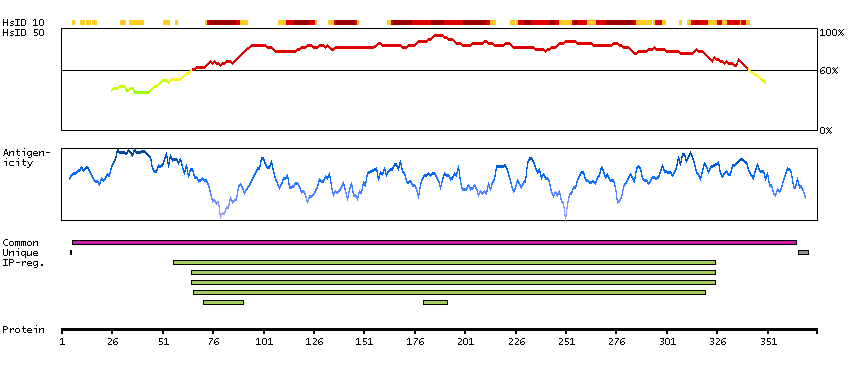
This gene encodes a protein belonging to the raf/mil family of serine/threonine protein kinases. This protein plays a role in regulating the MAP kinase/ERKs signaling pathway, which affects cell division, differentiation, and secretion. Mutations in this gene are associated with cardiofaciocutaneous syndrome, a disease characterized by heart defects, mental retardation and a distinctive facial appearance. Mutations in this gene have also been associated with various cancers, including non-Hodgkin lymphoma, colorectal cancer, malignant melanoma, thyroid carcinoma, non-small cell lung carcinoma, and adenocarcinoma of lung. A pseudogene, which is located on chromosome X, has been identified for this gene. [provided by RefSeq, Jul 2008]
Enzymes ENZYME proteins Transferases Kinases TKL Ser/Thr protein kinases Predicted intracellular proteins Cancer-related genes Mutated cancer genes Mutational cancer driver genes COSMIC somatic mutations in cancer genes COSMIC Somatic Mutations COSMIC Other Mutations COSMIC Missense Mutations COSMIC Translocations Disease related genes FDA approved drug targets Small molecule drugs Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000165 [MAPK cascade] GO:0000186 [activation of MAPKK activity] GO:0002318 [myeloid progenitor cell differentiation] GO:0004672 [protein kinase activity] GO:0004674 [protein serine/threonine kinase activity] GO:0004709 [MAP kinase kinase kinase activity] GO:0005057 [receptor signaling protein activity] GO:0005509 [calcium ion binding] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005634 [nucleus] GO:0005737 [cytoplasm] GO:0005739 [mitochondrion] GO:0005829 [cytosol] GO:0005886 [plasma membrane] GO:0006468 [protein phosphorylation] GO:0007165 [signal transduction] GO:0007173 [epidermal growth factor receptor signaling pathway] GO:0007264 [small GTPase mediated signal transduction] GO:0007265 [Ras protein signal transduction] GO:0007268 [synaptic transmission] GO:0007411 [axon guidance] GO:0008286 [insulin receptor signaling pathway] GO:0008542 [visual learning] GO:0008543 [fibroblast growth factor receptor signaling pathway] GO:0009887 [organ morphogenesis] GO:0010628 [positive regulation of gene expression] GO:0010764 [negative regulation of fibroblast migration] GO:0015758 [glucose transport] GO:0016020 [membrane] GO:0030154 [cell differentiation] GO:0030878 [thyroid gland development] GO:0031434 [mitogen-activated protein kinase kinase binding] GO:0033138 [positive regulation of peptidyl-serine phosphorylation] GO:0035019 [somatic stem cell population maintenance] GO:0035556 [intracellular signal transduction] GO:0035690 [cellular response to drug] GO:0038095 [Fc-epsilon receptor signaling pathway] GO:0042127 [regulation of cell proliferation] GO:0042802 [identical protein binding] GO:0043005 [neuron projection] GO:0043066 [negative regulation of apoptotic process] GO:0043367 [CD4-positive, alpha-beta T cell differentiation] GO:0043368 [positive T cell selection] GO:0043434 [response to peptide hormone] GO:0043524 [negative regulation of neuron apoptotic process] GO:0044297 [cell body] GO:0045087 [innate immune response] GO:0046632 [alpha-beta T cell differentiation] GO:0046982 [protein heterodimerization activity] GO:0048010 [vascular endothelial growth factor receptor signaling pathway] GO:0048011 [neurotrophin TRK receptor signaling pathway] GO:0048538 [thymus development] GO:0048679 [regulation of axon regeneration] GO:0048680 [positive regulation of axon regeneration] GO:0050772 [positive regulation of axonogenesis] GO:0051291 [protein heterooligomerization] GO:0051496 [positive regulation of stress fiber assembly] GO:0051591 [response to cAMP] GO:0060291 [long-term synaptic potentiation] GO:0060323 [head morphogenesis] GO:0060324 [face development] GO:0070374 [positive regulation of ERK1 and ERK2 cascade] GO:0071277 [cellular response to calcium ion] GO:0090150 [establishment of protein localization to membrane] GO:1900026 [positive regulation of substrate adhesion-dependent cell spreading] GO:2000301 [negative regulation of synaptic vesicle exocytosis] GO:2000352 [negative regulation of endothelial cell apoptotic process]
Predicted intracellular proteins Cancer-related genes Mutated cancer genes Mutational cancer driver genes COSMIC somatic mutations in cancer genes COSMIC Somatic Mutations COSMIC Other Mutations COSMIC Missense Mutations COSMIC Translocations Protein evidence (Ezkurdia et al 2014)