We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
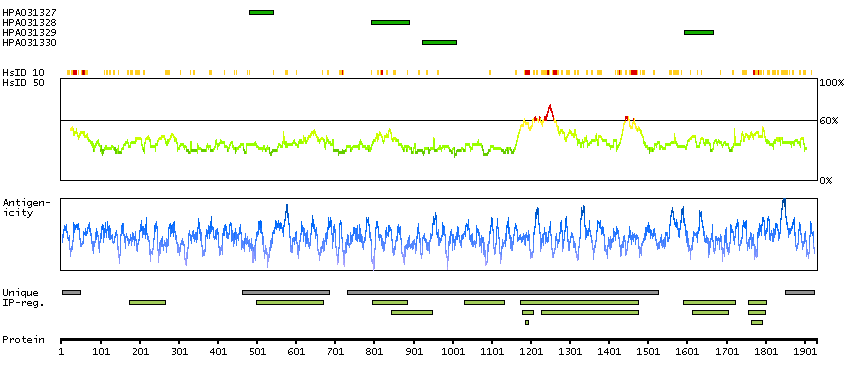
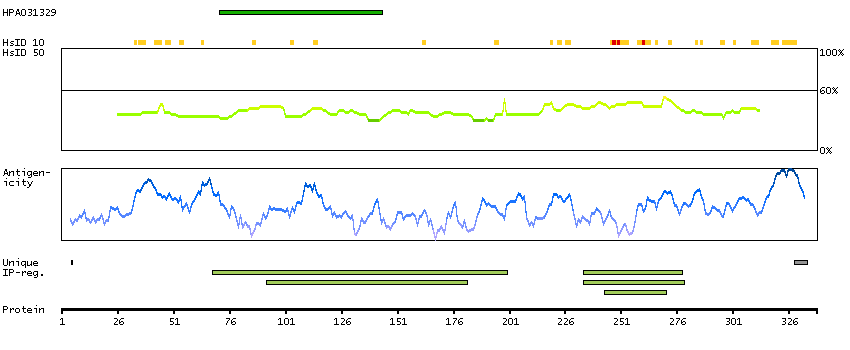
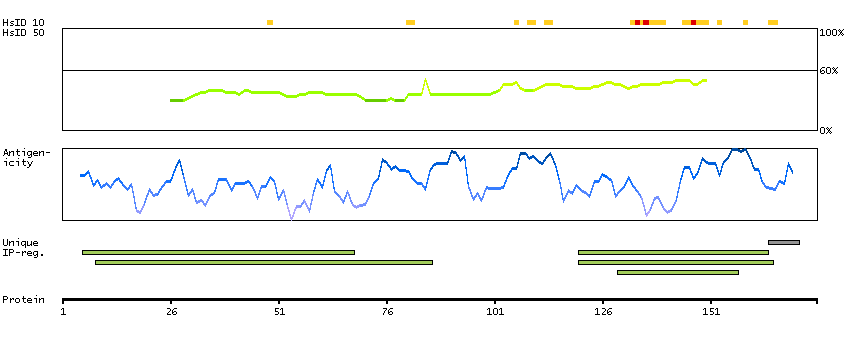
C3 and PZP-like, alpha-2-macroglobulin domain containing 8 (HGNC Symbol)
Entrez gene summary
CPAMD8 belongs to the complement component-3 (C3; MIM 120700)/alpha-2-macroglobulin (A2M; MIM 103950) family of proteins, which are involved in innate immunity and damage control. Complement components recognize and eliminate pathogens by direct binding or by mediating opsonization/phagocytosis and intracellular killing, and A2M is a broad-spectrum protease inhibitor (Li et al., 2004 [PubMed 15177561]).[supplied by OMIM, Mar 2008]