We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
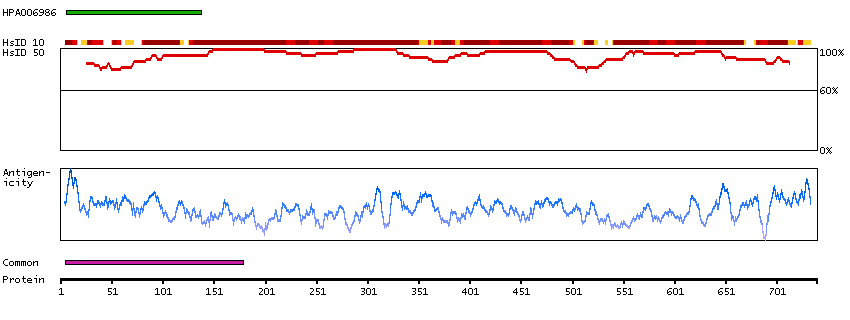
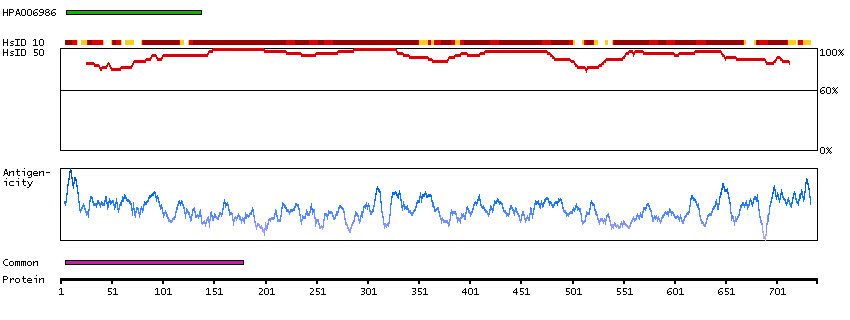
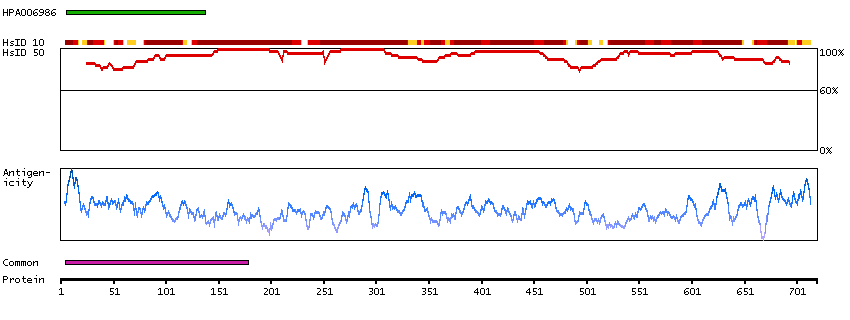
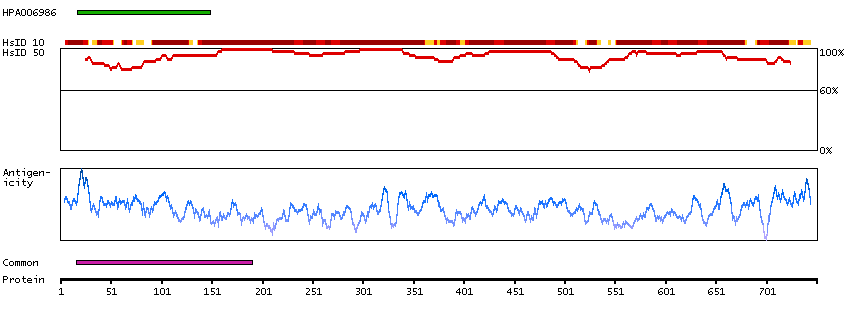
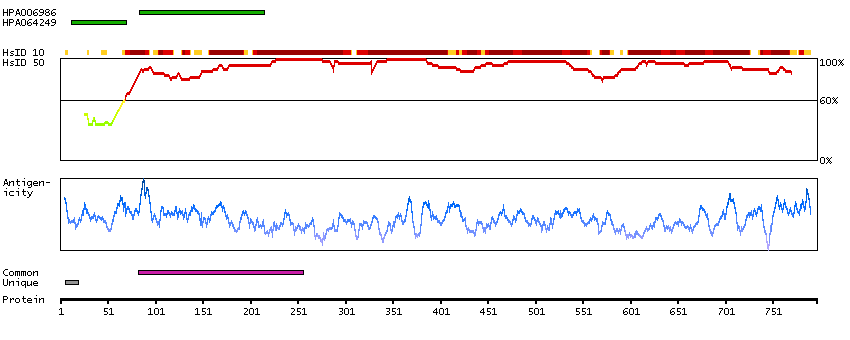
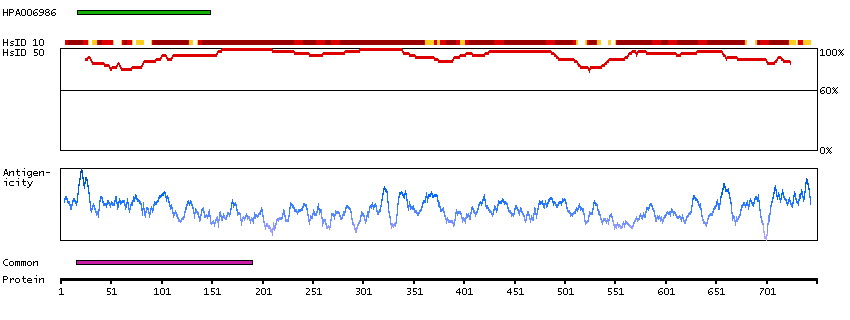
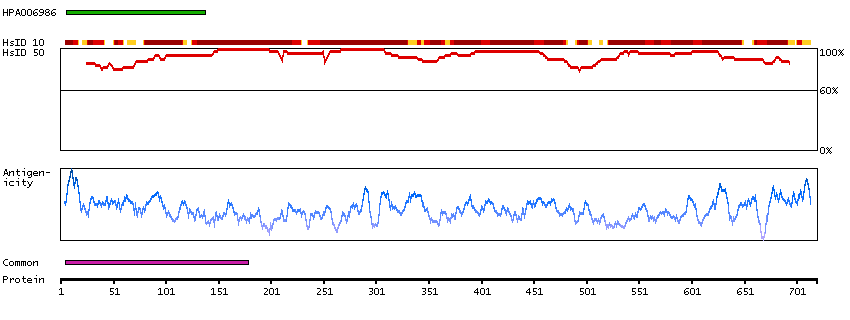
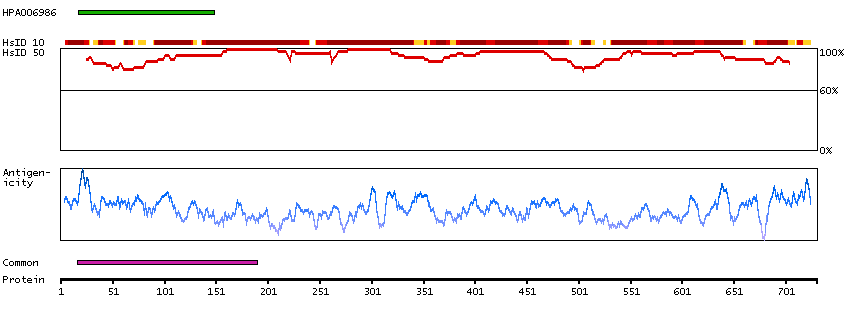
The encoded gene product presumably interacts with YY1 protein; however, its exact function is not known. Alternative splicing results in multiple transcript variants encoding different isoforms. [provided by RefSeq, Jul 2008]