We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
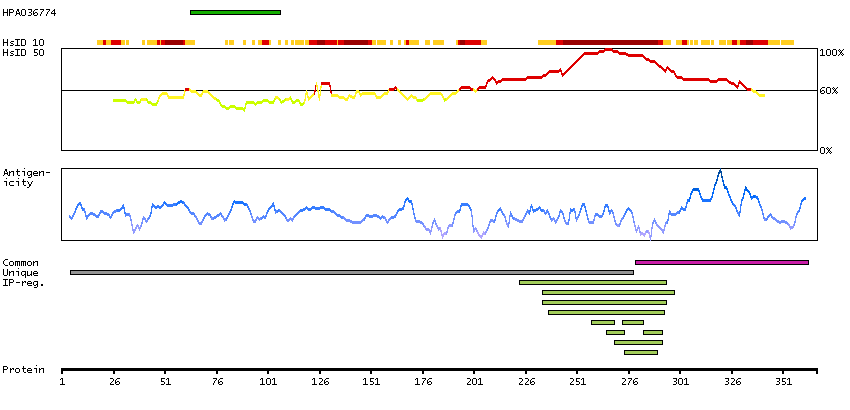
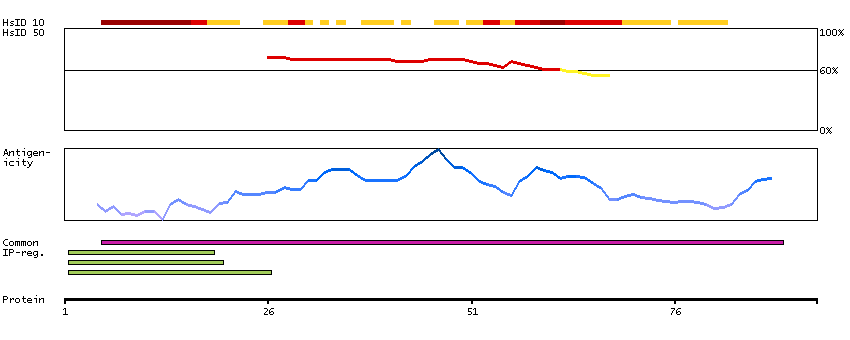
In the pancreas, NKX6.1 is required for the development of beta cells and is a potent bifunctional transcription regulator that binds to AT-rich sequences within the promoter region of target genes Iype et al. (2004) [PubMed 15056733].[supplied by OMIM, Mar 2008]