We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
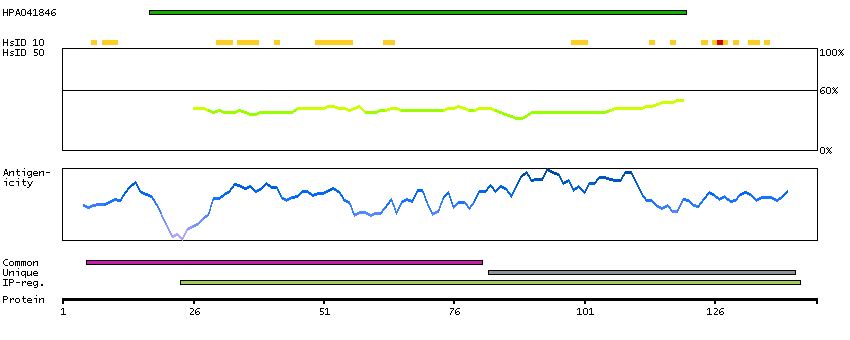
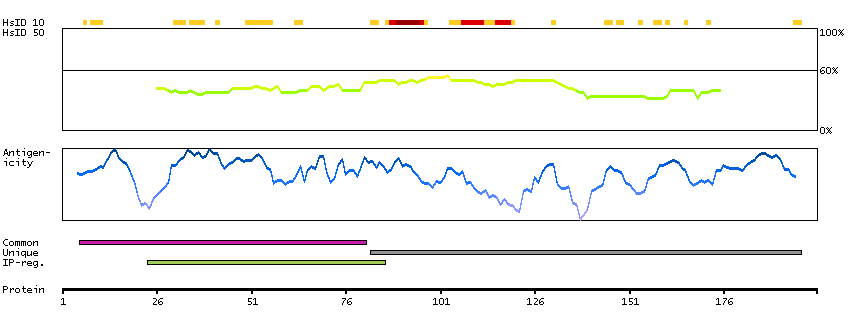
Protein phosphatase 1, regulatory (inhibitor) subunit 14D (HGNC Symbol)
Entrez gene summary
Protein phosphatase-1 (PP1; see MIM 176875) is a major cellular phosphatase that reverses serine/threonine protein phosphorylation. PPP1R14D is a PP1 inhibitor that itself is regulated by phosphorylation (Liu et al., 2004 [PubMed 12974676]).[supplied by OMIM, Feb 2010]