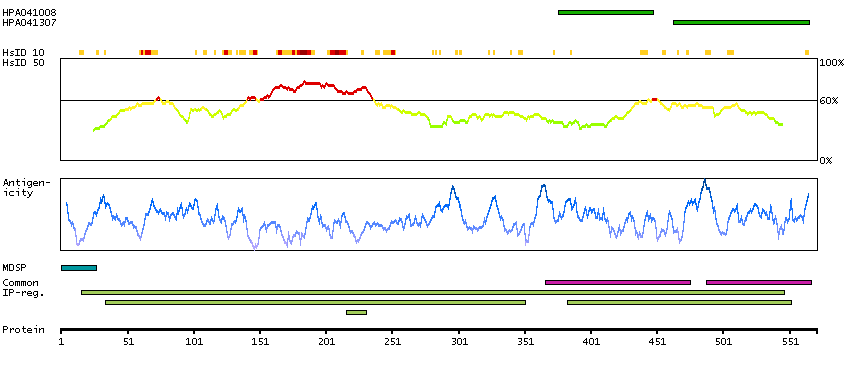
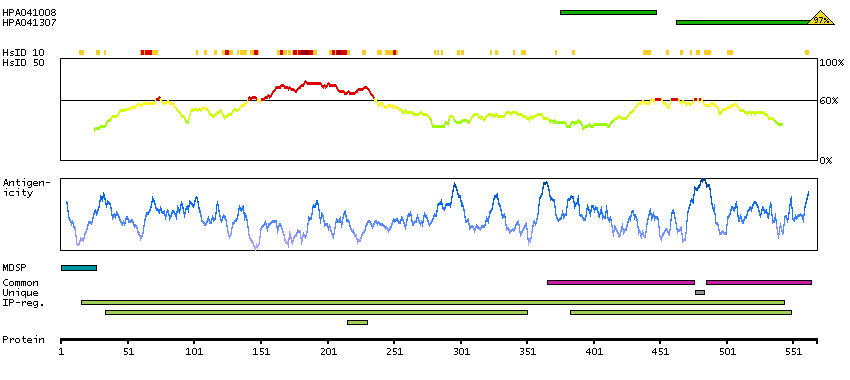
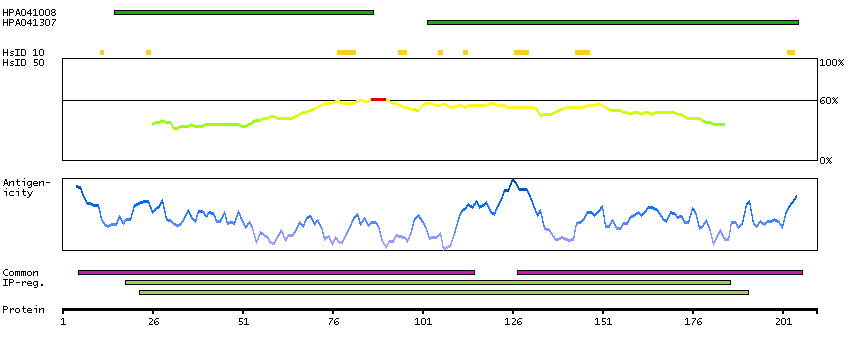
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
RNA tissue category: Group enriched (colon, kidney, liver, salivary gland, skeletal muscle, small intestine)
FANTOM5 dataset
Organ
Expression
Alphabetical
RNA tissue category: Tissue enhanced (colon, small intestine)
GENE INFORMATION
Gene name
CES3 (HGNC Symbol)
Synonyms
ES31, FLJ21736
Description
Carboxylesterase 3 (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the carboxylesterase large family. The family members are responsible for the hydrolysis or transesterification of various xenobiotics, such as cocaine and heroin, and endogenous substrates with ester, thioester, or amide bonds. They may participate in fatty acyl and cholesterol ester metabolism, and may play a role in the blood-brain barrier system. This gene is expressed in several tissues, particularly in colon, trachea and in brain, and the protein participates in colon and neural drug metabolism. Multiple alternatively spliced transcript variants encoding distinct isoforms have been reported, but the biological validity and/or full-length nature of some variants have not been determined.[provided by RefSeq, Jun 2010]