We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
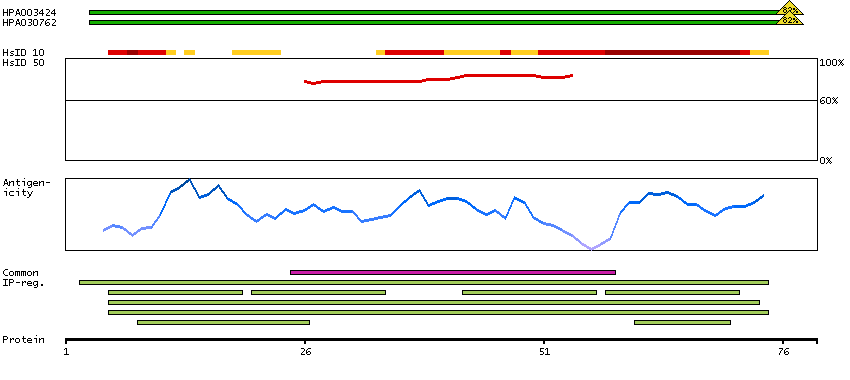
CDC28 protein kinase regulatory subunit 1B (HGNC Symbol)
Entrez gene summary
CKS1B protein binds to the catalytic subunit of the cyclin dependent kinases and is essential for their biological function. The CKS1B mRNA is found to be expressed in different patterns through the cell cycle in HeLa cells, which reflects a specialized role for the encoded protein. At least two transcript variants have been identified for this gene, and it appears that only one of them encodes a protein. [provided by RefSeq, Sep 2008]
Predicted intracellular proteins Cancer-related genes Candidate cancer biomarkers Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000079 [regulation of cyclin-dependent protein serine/threonine kinase activity] GO:0000082 [G1/S transition of mitotic cell cycle] GO:0000278 [mitotic cell cycle] GO:0005515 [protein binding] GO:0005654 [nucleoplasm] GO:0007049 [cell cycle] GO:0008283 [cell proliferation] GO:0016538 [cyclin-dependent protein serine/threonine kinase regulator activity] GO:0051301 [cell division]