We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
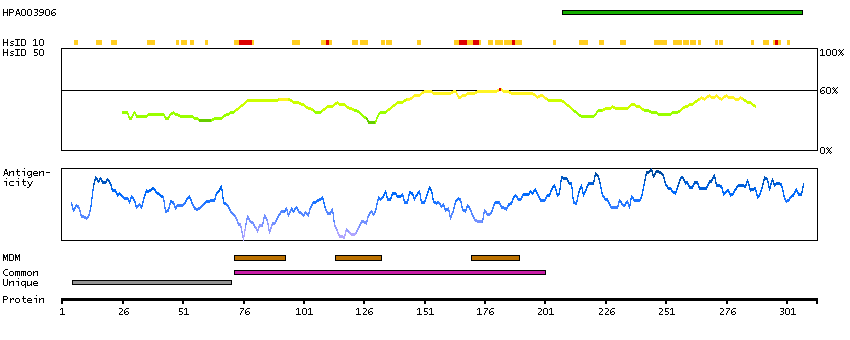
B-cell receptor-associated protein 31 (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the B-cell receptor associated protein 31 superfamily. The encoded protein is a multi-pass transmembrane protein of the endoplasmic reticulum that is involved in the anterograde transport of membrane proteins from the endoplasmic reticulum to the Golgi and in caspase 8-mediated apoptosis. Microdeletions in this gene are associated with contiguous ABCD1/DXS1375E deletion syndrome (CADDS), a neonatal disorder. Alternative splicing of this gene results in multiple transcript variants. Two related pseudogenes have been identified on chromosome 16. [provided by RefSeq, Jan 2012]