We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
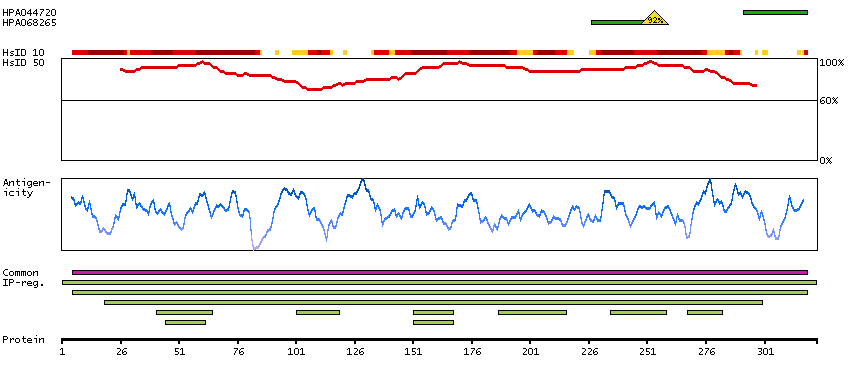
Aldo-keto reductase family 1, member C4 (HGNC Symbol)
Entrez gene summary
This gene encodes a member of the aldo/keto reductase superfamily, which consists of more than 40 known enzymes and proteins. These enzymes catalyze the conversion of aldehydes and ketones to their corresponding alcohols by utilizing NADH and/or NADPH as cofactors. The enzymes display overlapping but distinct substrate specificity. This enzyme catalyzes the bioreduction of chlordecone, a toxic organochlorine pesticide, to chlordecone alcohol in liver. This gene shares high sequence identity with three other gene members and is clustered with those three genes at chromosome 10p15-p14. [provided by RefSeq, Jul 2008]
P17516 [Direct mapping] Aldo-keto reductase family 1 member C4
Show all
Enzymes ENZYME proteins Oxidoreductases Predicted intracellular proteins Plasma proteins Disease related genes Potential drug targets Protein evidence (Ezkurdia et al 2014)
P17516 [Direct mapping] Aldo-keto reductase family 1 member C4
Show all
Enzymes ENZYME proteins Oxidoreductases Predicted intracellular proteins Plasma proteins Disease related genes Potential drug targets Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)