We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
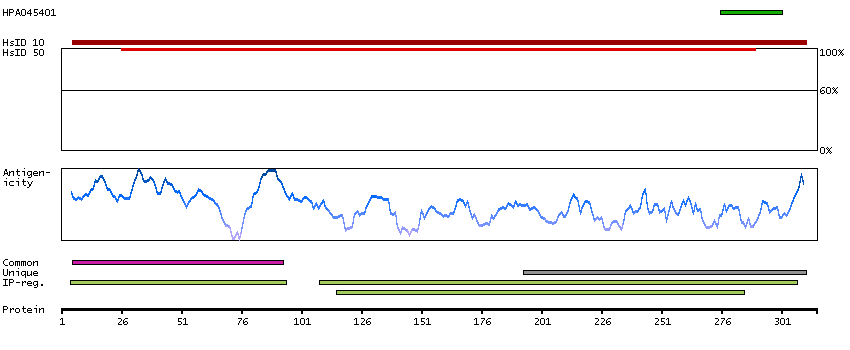
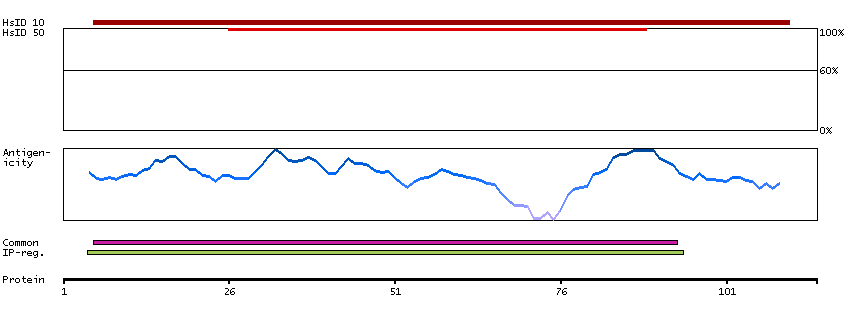
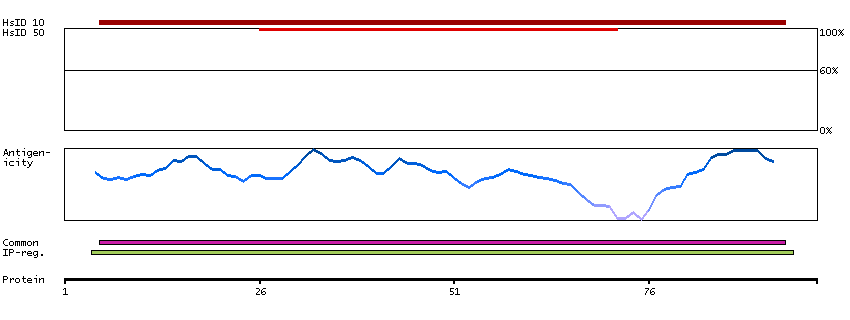
MAGEA9B is a duplication of the MAGEA9 gene (MIM 300342) on chromosome Xq28. The 2 copies are separated by about 194 kb (Hartz, 2009).[supplied by OMIM, Mar 2009]