We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
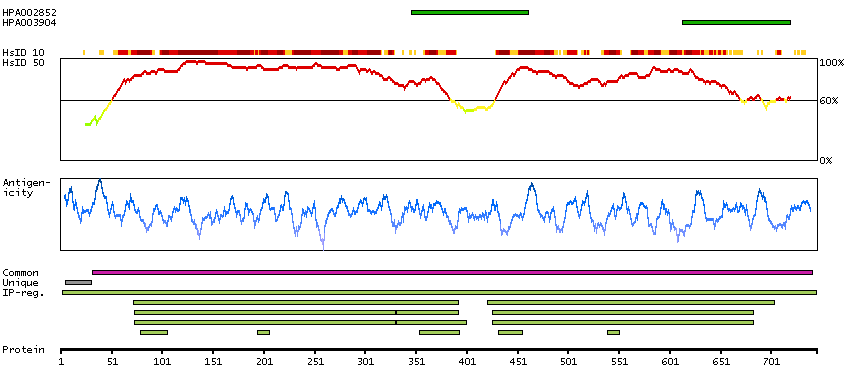
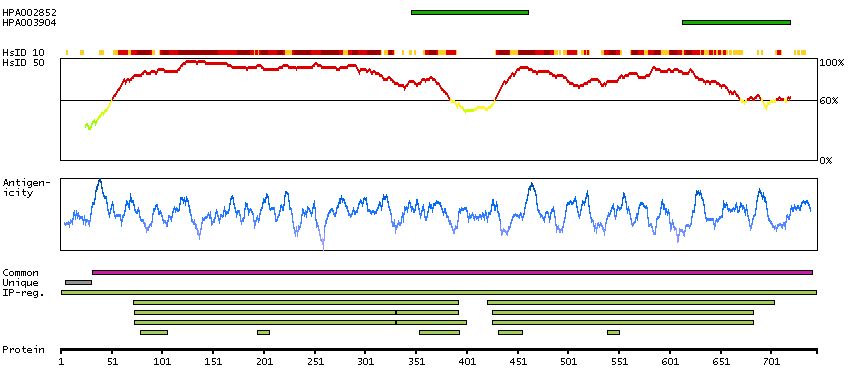
Ribosomal protein S6 kinase, 90kDa, polypeptide 6 (HGNC Symbol)
Entrez gene summary
This gene encodes a member of ribosomal S6 kinase family, serine-threonine protein kinases which are regulated by growth factors. The encoded protein may be distinct from other members of this family, however, as studies suggest it is not growth factor dependent and may not participate in the same signaling pathways. [provided by RefSeq, Jan 2010]