We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
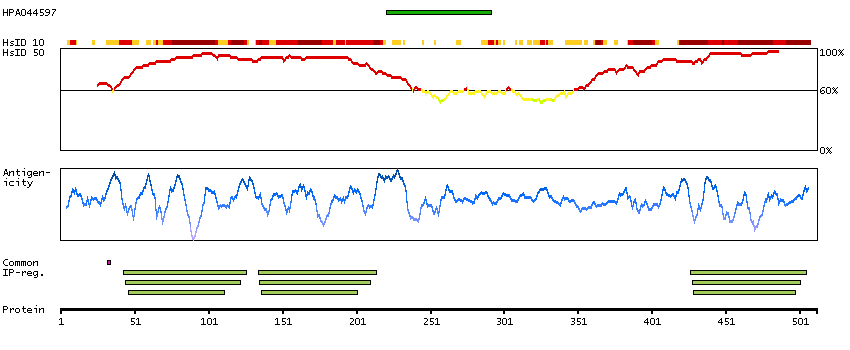
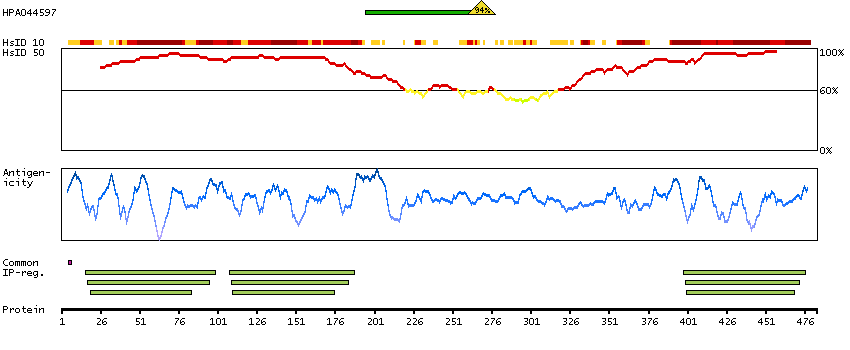
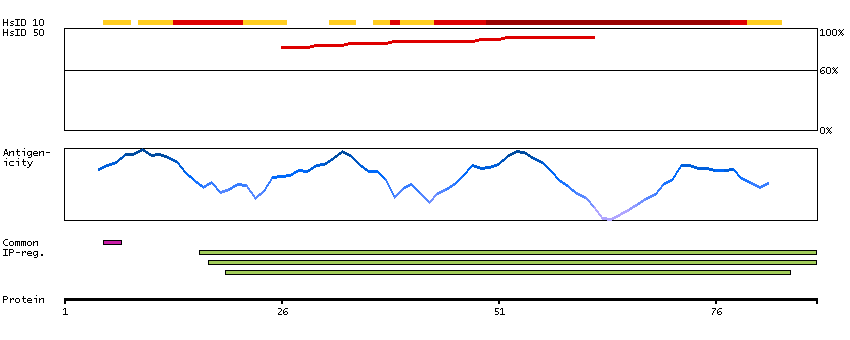
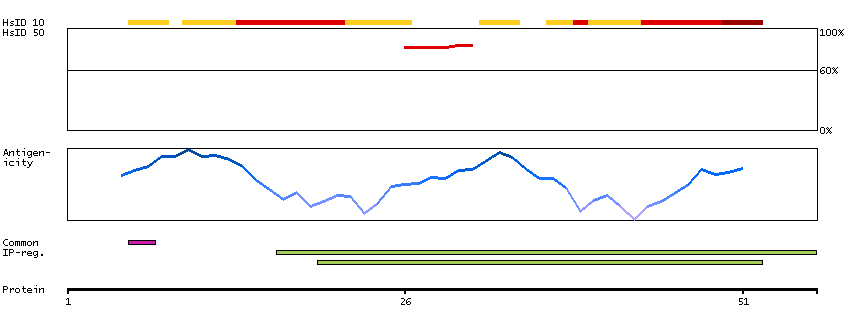
Members of the CELF/BRUNOL protein family contain two N-terminal RNA recognition motif (RRM) domains, one C-terminal RRM domain, and a divergent segment of 160-230 aa between the second and third RRM domains. Members of this protein family regulate pre-mRNA alternative splicing and may also be involved in mRNA editing, and translation. This gene may play a role in myotonic dystrophy type 1 (DM1) via interactions with the dystrophia myotonica-protein kinase (DMPK) gene. Alternative splicing results in multiple transcript variants encoding different isoforms. [provided by RefSeq, Jul 2008]