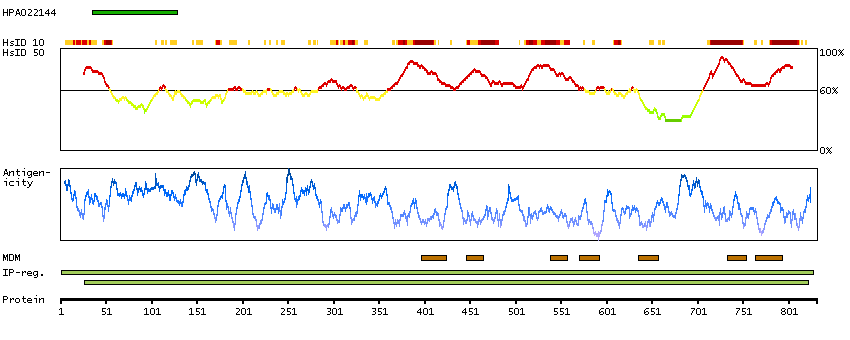
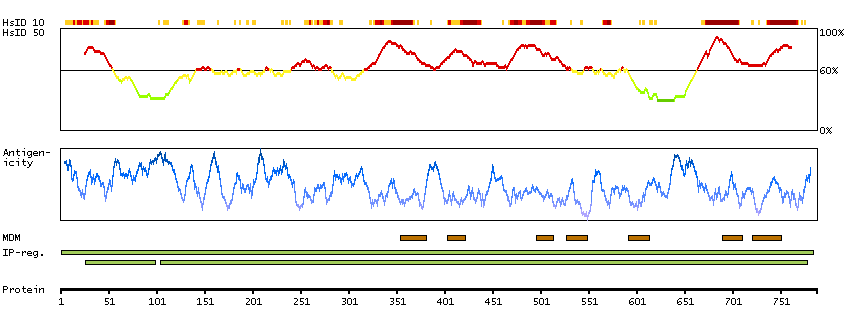
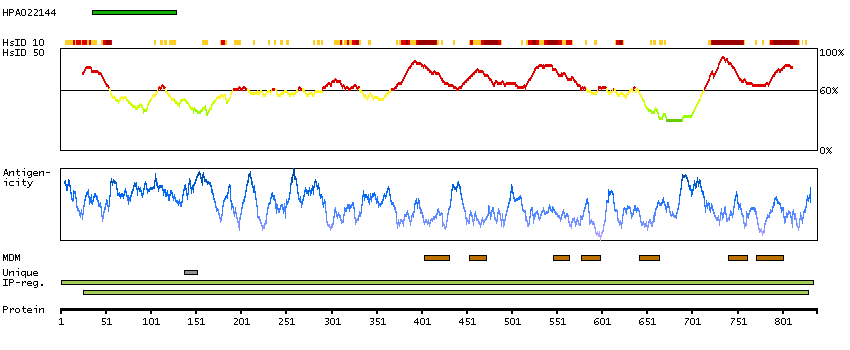
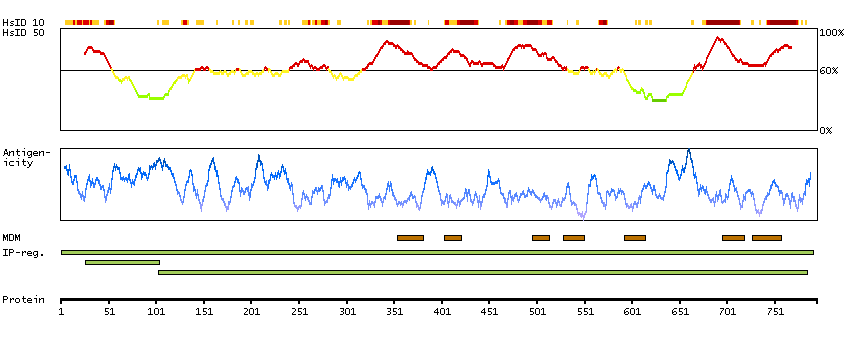
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
This gene encodes a component of vacuolar ATPase (V-ATPase), a multisubunit enzyme that mediates acidification of eukaryotic intracellular organelles. V-ATPase dependent organelle acidification is necessary for such intracellular processes as protein sorting, zymogen activation, receptor-mediated endocytosis, and synaptic vesicle proton gradient generation. V-ATPase is composed of a cytosolic V1 domain and a transmembrane V0 domain. The V1 domain consists of three A and three B subunits, two G subunits plus the C, D, E, F, and H subunits. The V1 domain contains the ATP catalytic site. The V0 domain consists of five different subunits: a, c, c', c"", and d. Additional isoforms of many of the V1 and V0 subunit proteins are encoded by multiple genes or alternatively spliced transcript variants. This gene encodes one of three A subunit proteins and the encoded protein is associated with clathrin-coated vesicles. Three transcript variants encoding different isoforms have been found for this gene. [provided by RefSeq, Jul 2008]