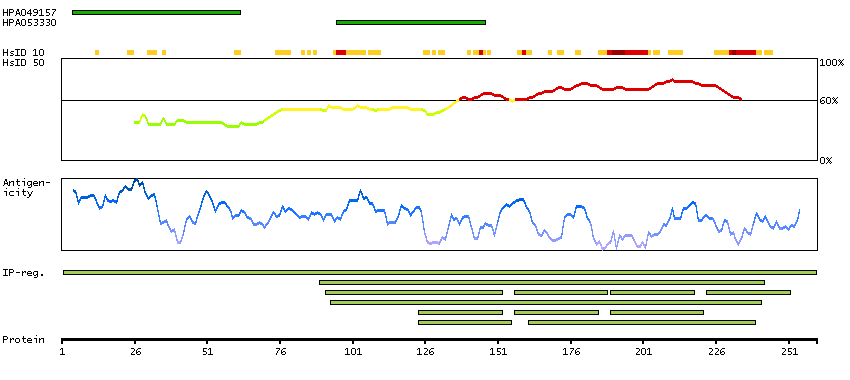
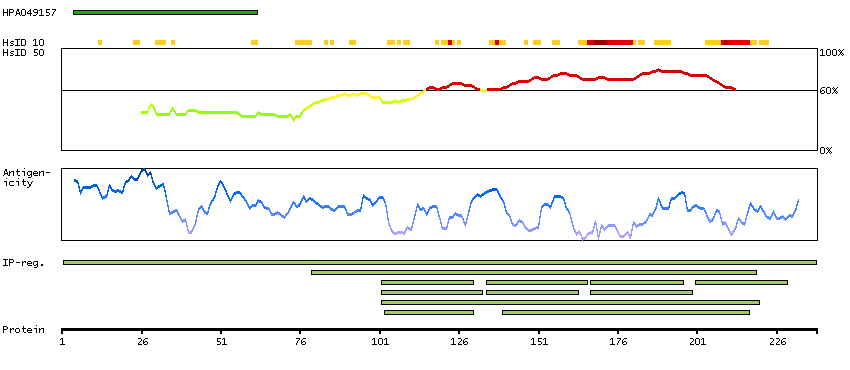
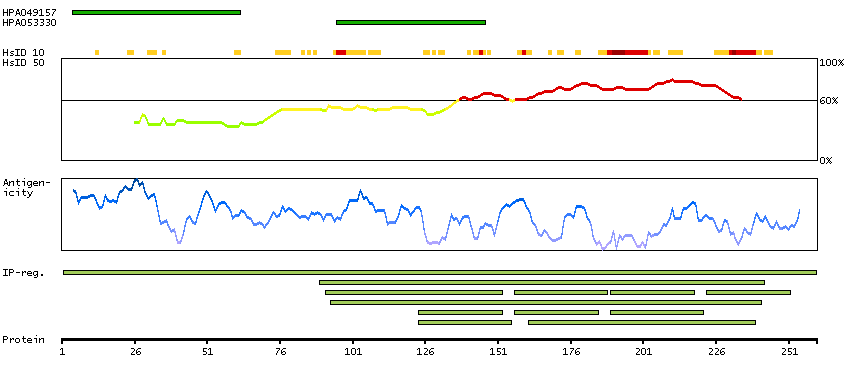
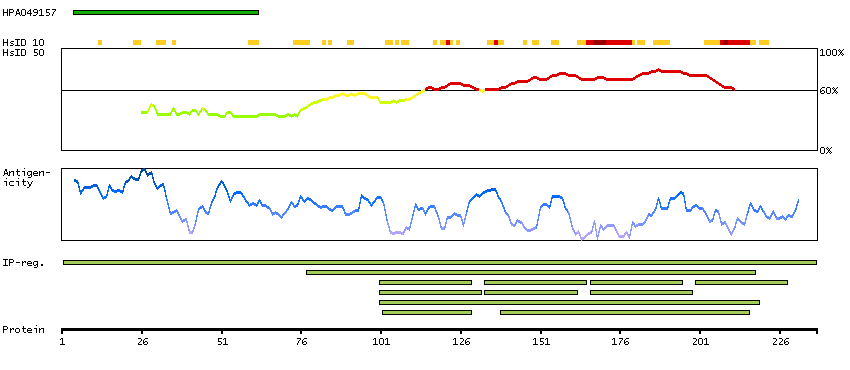
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Regulatory factor X-associated ankyrin-containing protein (HGNC Symbol)
Entrez gene summary
Major histocompatibility (MHC) class II molecules are transmembrane proteins that have a central role in development and control of the immune system. The protein encoded by this gene, along with regulatory factor X-associated protein and regulatory factor-5, forms a complex that binds to the X box motif of certain MHC class II gene promoters and activates their transcription. Once bound to the promoter, this complex associates with the non-DNA-binding factor MHC class II transactivator, which controls the cell type specificity and inducibility of MHC class II gene expression. This protein contains ankyrin repeats involved in protein-protein interactions. Mutations in this gene have been linked to bare lymphocyte syndrome type II, complementation group B. Multiple alternatively spliced transcript variants encoding different isoforms have been described for this gene. [provided by RefSeq, Jul 2013]