We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
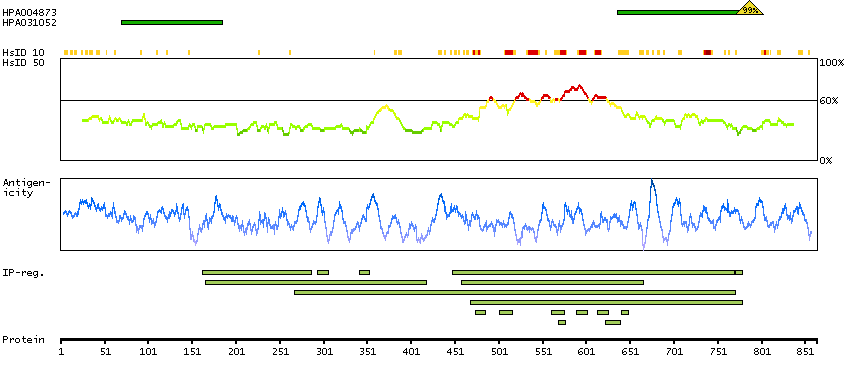
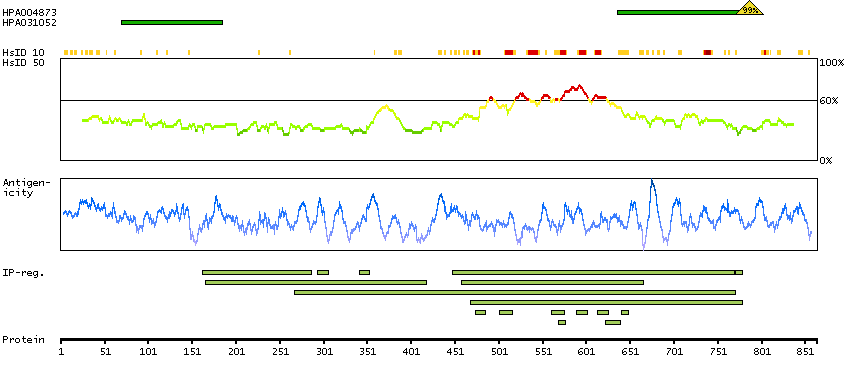
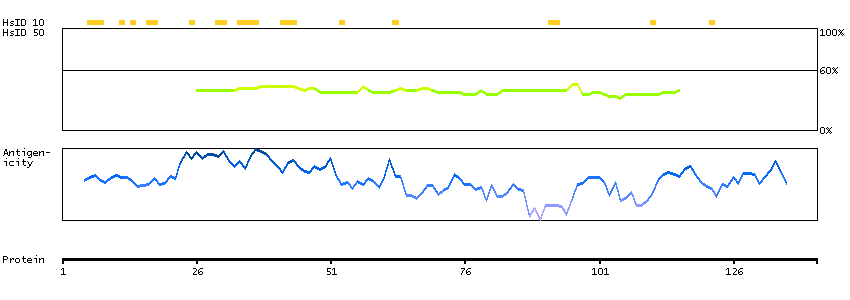
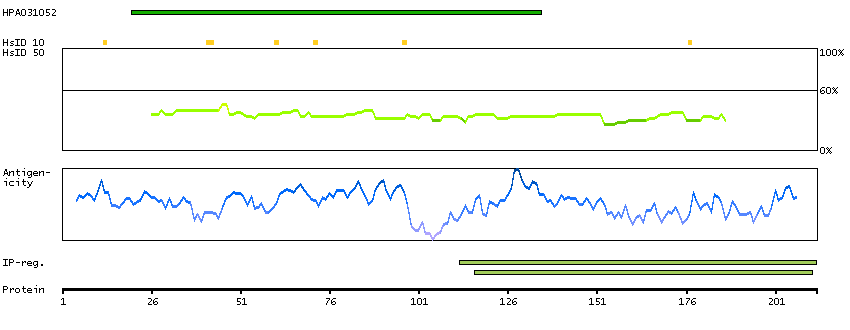
The protein encoded by this gene is one of the highly conserved mini-chromosome maintenance proteins (MCM) that are essential for the initiation of eukaryotic genome replication. The hexameric protein complex formed by MCM proteins is a key component of the pre-replication complex (pre_RC) and may be involved in the formation of replication forks and in the recruitment of other DNA replication related proteins. The MCM complex consisting of this protein and MCM2, 6 and 7 proteins possesses DNA helicase activity, and may act as a DNA unwinding enzyme. The phosphorylation of this protein by CDC2 kinase reduces the DNA helicase activity and chromatin binding of the MCM complex. This gene is mapped to a region on the chromosome 8 head-to-head next to the PRKDC/DNA-PK, a DNA-activated protein kinase involved in the repair of DNA double-strand breaks. Alternatively spliced transcript variants encoding the same protein have been reported. [provided by RefSeq, Jul 2008]
P33991 [Direct mapping] DNA replication licensing factor MCM4
Show all
Enzymes ENZYME proteins Hydrolases Predicted intracellular proteins Disease related genes Potential drug targets Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
P33991 [Direct mapping] DNA replication licensing factor MCM4
Show all
Enzymes ENZYME proteins Hydrolases Predicted intracellular proteins Disease related genes Potential drug targets Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)