We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
This gene encodes a RNA-editing deaminase that is a member of the cytidine deaminase family. The protein is involved in somatic hypermutation, gene conversion, and class-switch recombination of immunoglobulin genes. Defects in this gene are the cause of autosomal recessive hyper-IgM immunodeficiency syndrome type 2 (HIGM2). [provided by RefSeq, Feb 2009]
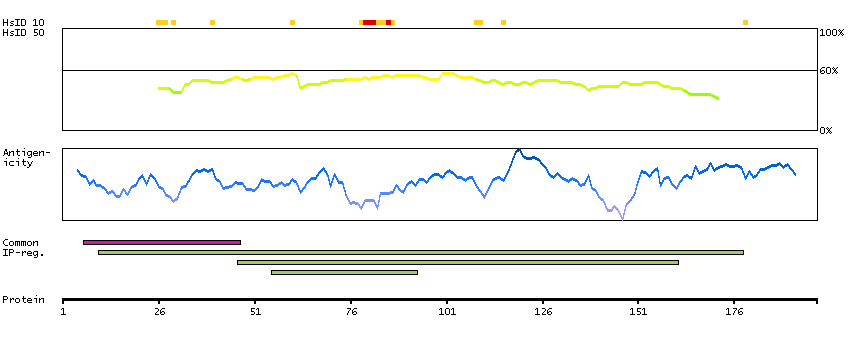
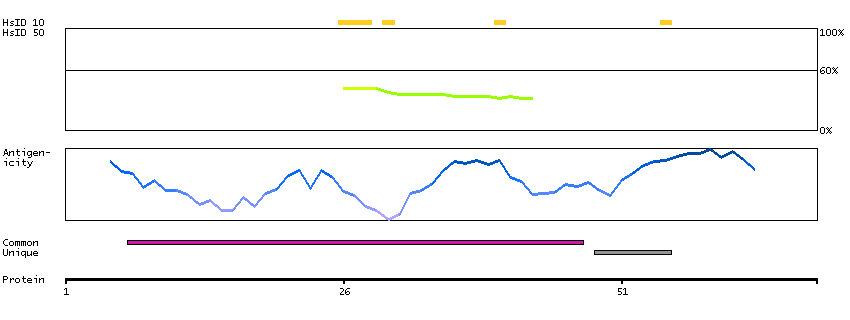
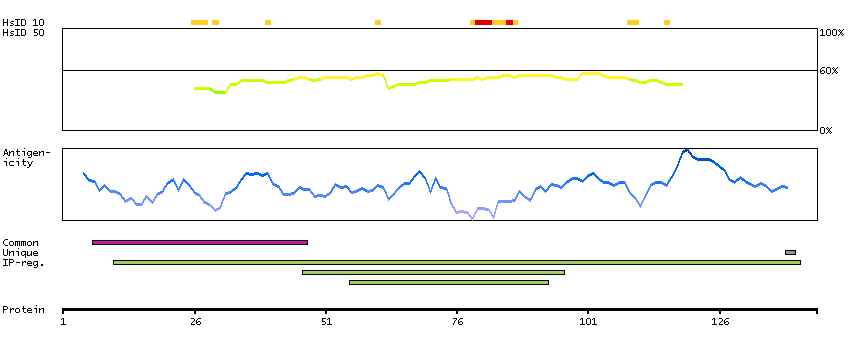
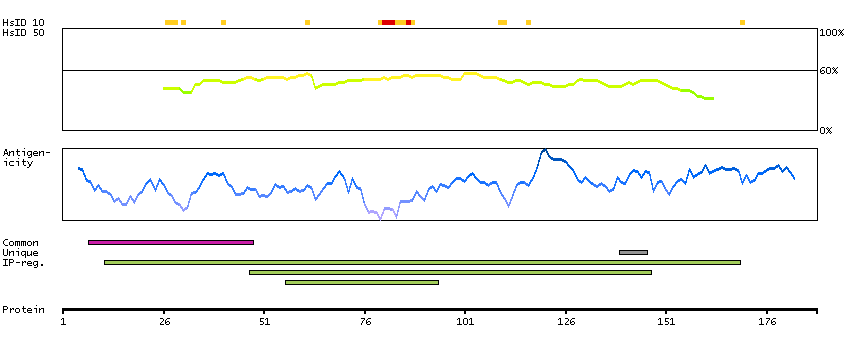
H0YFP1 [Direct mapping] Single-stranded DNA cytosine deaminase
Show all
Predicted intracellular proteins
Show all
GO:0008152 [metabolic process] GO:0008270 [zinc ion binding] GO:0016814 [hydrolase activity, acting on carbon-nitrogen (but not peptide) bonds, in cyclic amidines]