We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
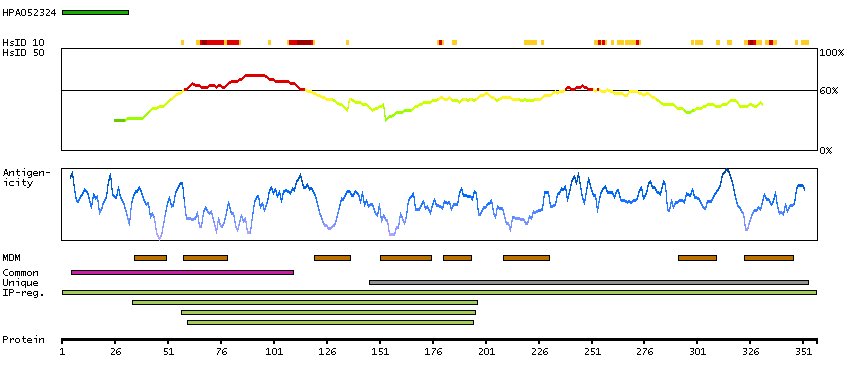
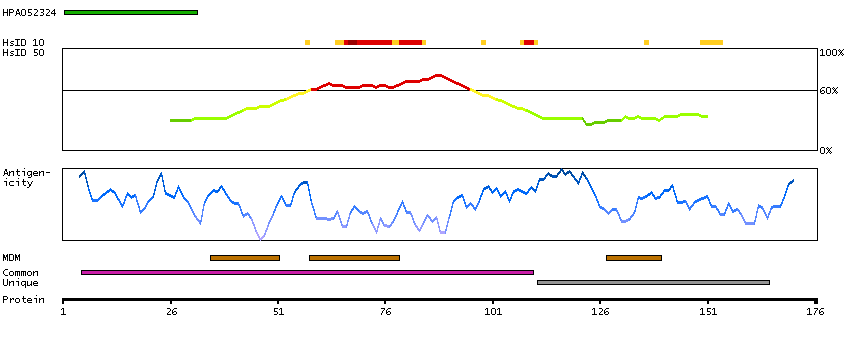
Glucose-6-phosphatase (G6Pase) is a multi-subunit integral membrane protein of the endoplasmic reticulum that is composed of a catalytic subunit and transporters for G6P, inorganic phosphate, and glucose. This gene (G6PC) is one of the three glucose-6-phosphatase catalytic-subunit-encoding genes in human: G6PC, G6PC2 and G6PC3. Glucose-6-phosphatase catalyzes the hydrolysis of D-glucose 6-phosphate to D-glucose and orthophosphate and is a key enzyme in glucose homeostasis, functioning in gluconeogenesis and glycogenolysis. Mutations in this gene cause glycogen storage disease type I (GSD1). This disease, also known as von Gierke disease, is a metabolic disorder characterized by severe hypoglycemia associated with the accumulation of glycogen and fat in the liver and kidneys.[provided by RefSeq, Feb 2011]