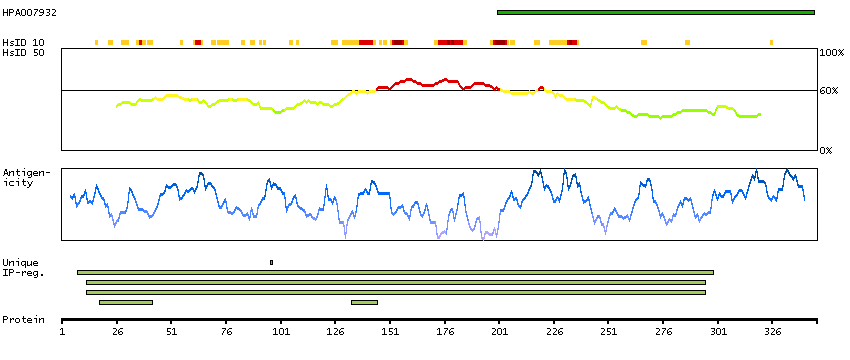
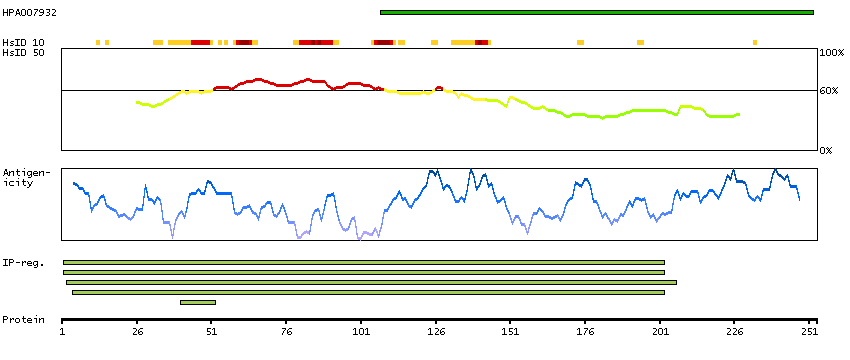
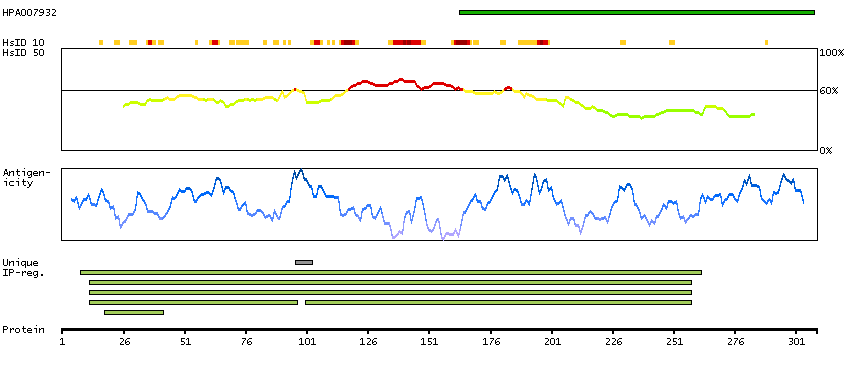
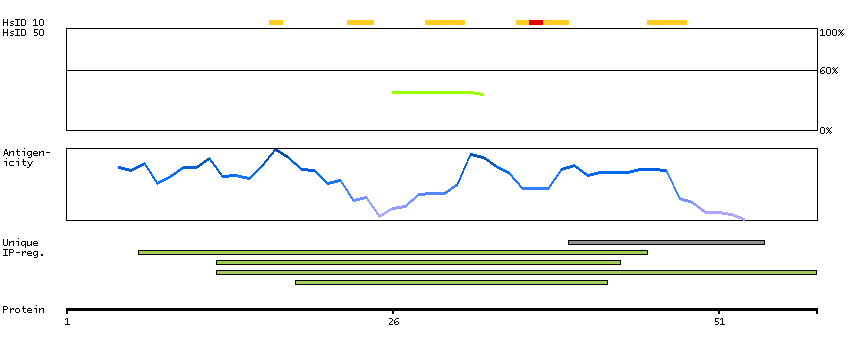
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
The protein encoded by this gene is a member of the cyclin-dependent protein kinase (CDK) family. CDK family members are highly similar to the gene products of Saccharomyces cerevisiae cdc28, and Schizosaccharomyces pombe cdc2, and are known to be important regulators of cell cycle progression. This protein forms a trimeric complex with cyclin H and MAT1, which functions as a Cdk-activating kinase (CAK). It is an essential component of the transcription factor TFIIH, that is involved in transcription initiation and DNA repair. This protein is thought to serve as a direct link between the regulation of transcription and the cell cycle. [provided by RefSeq, Jul 2008]
Enzymes ENZYME proteins Transferases Kinases CMGC Ser/Thr protein kinases MEMSAT-SVM predicted membrane proteins THUMBUP predicted membrane proteins Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0000079 [regulation of cyclin-dependent protein serine/threonine kinase activity] GO:0000082 [G1/S transition of mitotic cell cycle] GO:0000086 [G2/M transition of mitotic cell cycle] GO:0000278 [mitotic cell cycle] GO:0003713 [transcription coactivator activity] GO:0004672 [protein kinase activity] GO:0004693 [cyclin-dependent protein serine/threonine kinase activity] GO:0005515 [protein binding] GO:0005524 [ATP binding] GO:0005634 [nucleus] GO:0005654 [nucleoplasm] GO:0005675 [holo TFIIH complex] GO:0005737 [cytoplasm] GO:0005739 [mitochondrion] GO:0006281 [DNA repair] GO:0006283 [transcription-coupled nucleotide-excision repair] GO:0006289 [nucleotide-excision repair] GO:0006360 [transcription from RNA polymerase I promoter] GO:0006361 [transcription initiation from RNA polymerase I promoter] GO:0006362 [transcription elongation from RNA polymerase I promoter] GO:0006363 [termination of RNA polymerase I transcription] GO:0006366 [transcription from RNA polymerase II promoter] GO:0006367 [transcription initiation from RNA polymerase II promoter] GO:0006368 [transcription elongation from RNA polymerase II promoter] GO:0006370 [7-methylguanosine mRNA capping] GO:0006468 [protein phosphorylation] GO:0007050 [cell cycle arrest] GO:0008022 [protein C-terminus binding] GO:0008094 [DNA-dependent ATPase activity] GO:0008283 [cell proliferation] GO:0008353 [RNA polymerase II carboxy-terminal domain kinase activity] GO:0010467 [gene expression] GO:0016032 [viral process] GO:0016301 [kinase activity] GO:0030521 [androgen receptor signaling pathway] GO:0040029 [regulation of gene expression, epigenetic] GO:0045814 [negative regulation of gene expression, epigenetic] GO:0045893 [positive regulation of transcription, DNA-templated] GO:0045944 [positive regulation of transcription from RNA polymerase II promoter] GO:0048471 [perinuclear region of cytoplasm] GO:0050434 [positive regulation of viral transcription] GO:0050681 [androgen receptor binding] GO:0051301 [cell division] GO:0070911 [global genome nucleotide-excision repair]