We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
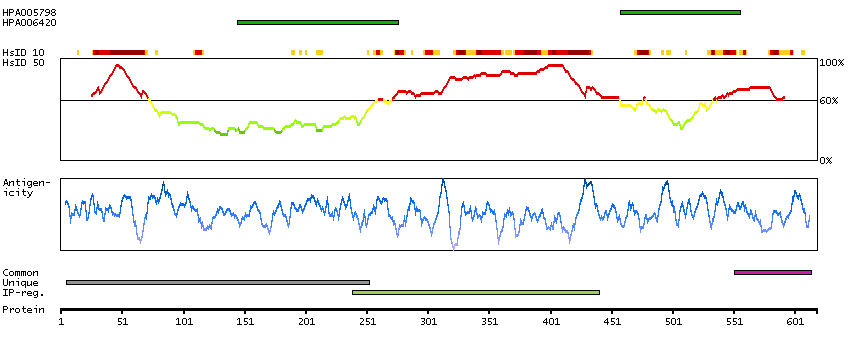
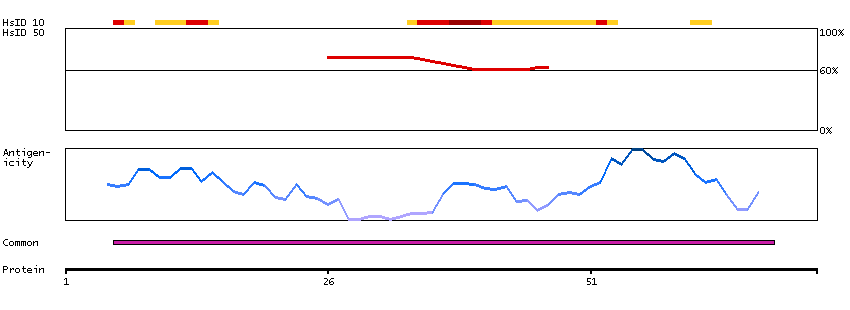
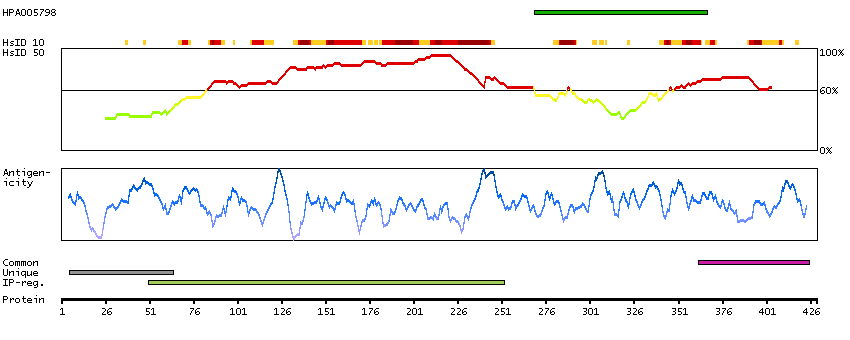
This gene encodes a member of the grainyhead family of transcription factors. The encoded protein can exist as a homodimer or can form heterodimers with sister-of-mammalian grainyhead or brother-of-mammalian grainyhead. This protein functions as a transcription factor during development. [provided by RefSeq, Jun 2009]