We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
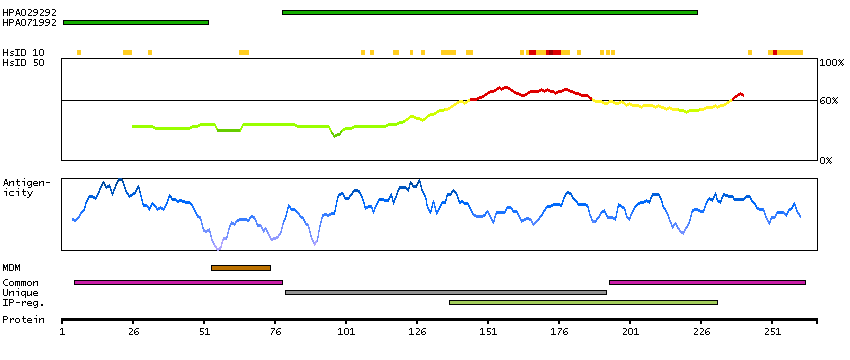
Amyloid precursor proteins are processed by beta-secretase and gamma-secretase to produce beta-amyloid peptides which form the characteristic plaques of Alzheimer disease. This gene encodes a transmembrane protein which is processed at the C-terminus by furin or furin-like proteases to produce a small secreted peptide which inhibits the deposition of beta-amyloid. Mutations which result in extension of the C-terminal end of the encoded protein, thereby increasing the size of the secreted peptide, are associated with two neurogenerative diseases, familial British dementia and familial Danish dementia. [provided by RefSeq, Oct 2009]