We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
RNA tissue category: Group enriched (cerebellum, cerebral cortex, hippocampus, hypothalamus)
FANTOM5 dataset
Organ
Expression
Alphabetical
RNA tissue category: Group enriched (brain, cerebellum, hippocampus)
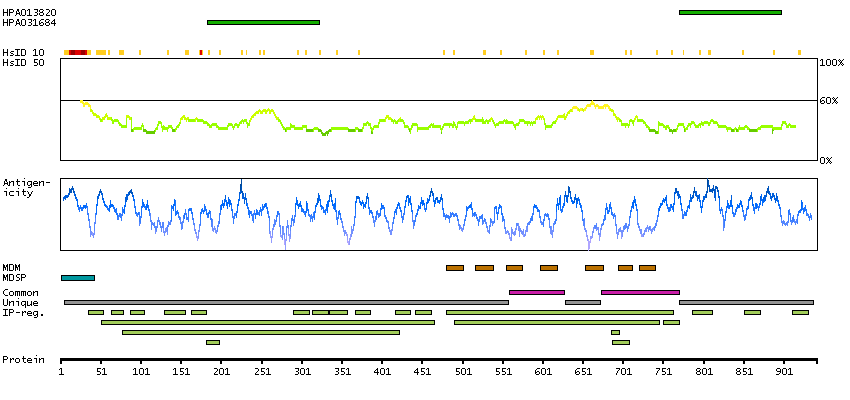
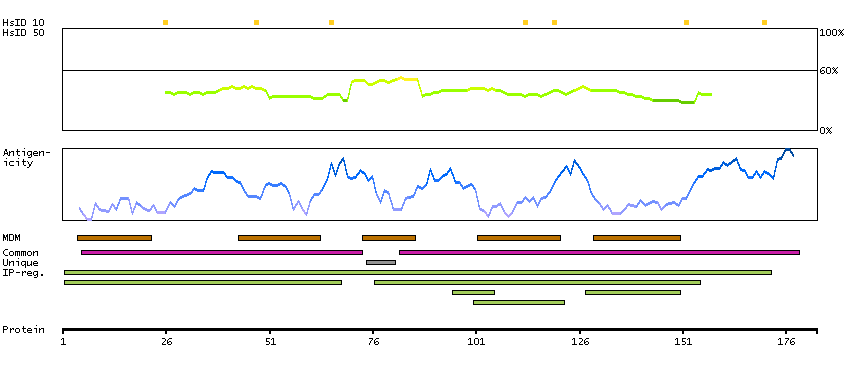
GENE INFORMATION
Gene name
GABBR2 (HGNC Symbol)
Synonyms
GABABR2, GPR51, GPRC3B, HG20
Description
Gamma-aminobutyric acid (GABA) B receptor, 2 (HGNC Symbol)
Entrez gene summary
The multi-pass membrane protein encoded by this gene belongs to the G-protein coupled receptor 3 family and GABA-B receptor subfamily. The GABA-B receptors inhibit neuronal activity through G protein-coupled second-messenger systems, which regulate the release of neurotransmitters, and the activity of ion channels and adenylyl cyclase. This receptor subunit forms an active heterodimeric complex with GABA-B receptor subunit 1, neither of which is effective on its own. Allelic variants of this gene have been associated with nicotine dependence.[provided by RefSeq, Jan 2010]