We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Aldehyde dehydrogenase 1 family, member L1 (HGNC Symbol)
Entrez gene summary
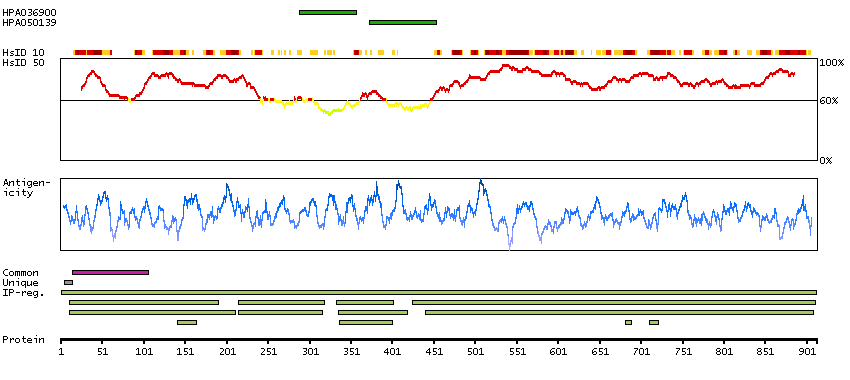
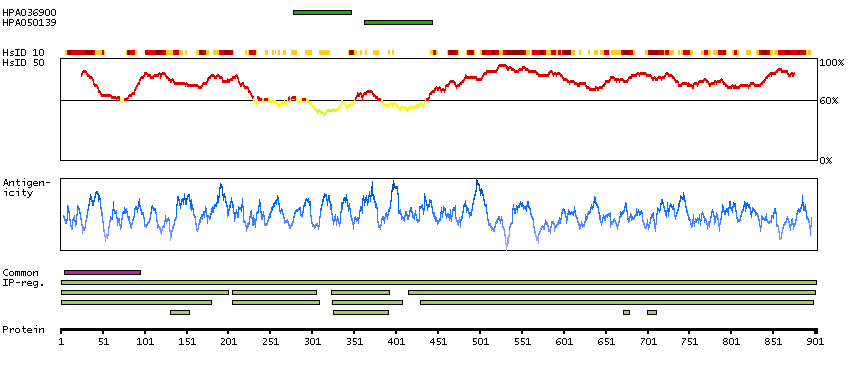
The protein encoded by this gene catalyzes the conversion of 10-formyltetrahydrofolate, nicotinamide adenine dinucleotide phosphate (NADP+), and water to tetrahydrofolate, NADPH, and carbon dioxide. The encoded protein belongs to the aldehyde dehydrogenase family. Loss of function or expression of this gene is associated with decreased apoptosis, increased cell motility, and cancer progression. There is an antisense transcript that overlaps on the opposite strand with this gene locus. Alternative splicing results in multiple transcript variants. [provided by RefSeq, Jun 2012]
Enzymes ENZYME proteins Oxidoreductases MEMSAT-SVM predicted membrane proteins SPOCTOPUS predicted membrane proteins Predicted intracellular proteins Plasma proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)