We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Eukaryotic translation initiation factor 4E (HGNC Symbol)
Entrez gene summary
The protein encoded by this gene is a component of the eukaryotic translation initiation factor 4F complex, which recognizes the 7-methylguanosine cap structure at the 5' end of messenger RNAs. The encoded protein aids in translation initiation by recruiting ribosomes to the 5'-cap structure. Association of this protein with the 4F complex is the rate-limiting step in translation initiation. This gene acts as a proto-oncogene, and its expression and activation is associated with transformation and tumorigenesis. Several pseudogenes of this gene are found on other chromosomes. Alternative splicing results in multiple transcript variants. [provided by RefSeq, Sep 2015]
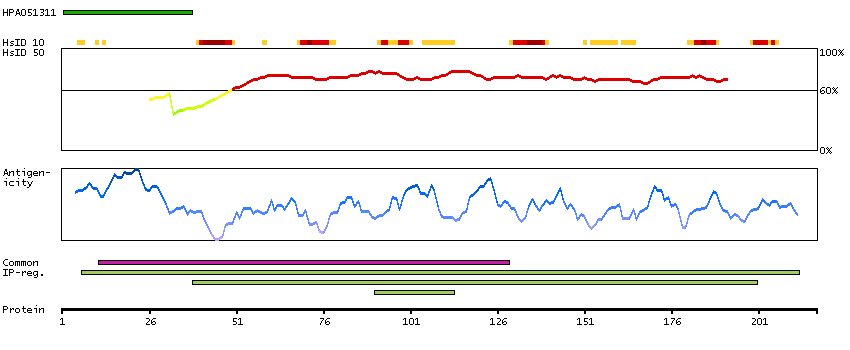
P06730 [Direct mapping] Eukaryotic translation initiation factor 4E
Show all
Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
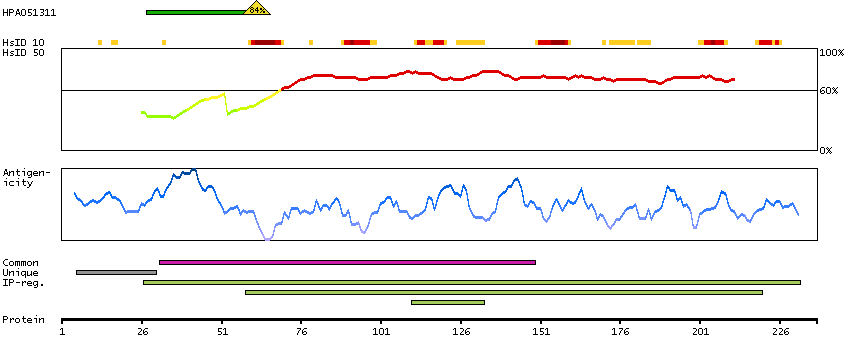
P06730 [Direct mapping] Eukaryotic translation initiation factor 4E X5D7E3 [Target identity:100%; Query identity:100%] Eukaryotic translation initiation factor 4E isoform A
Show all
Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
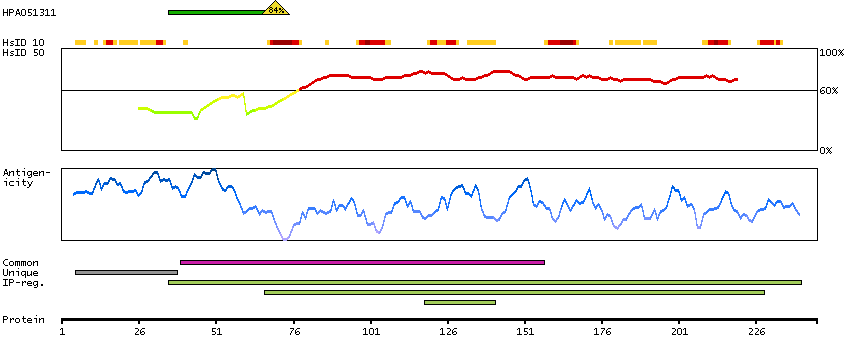
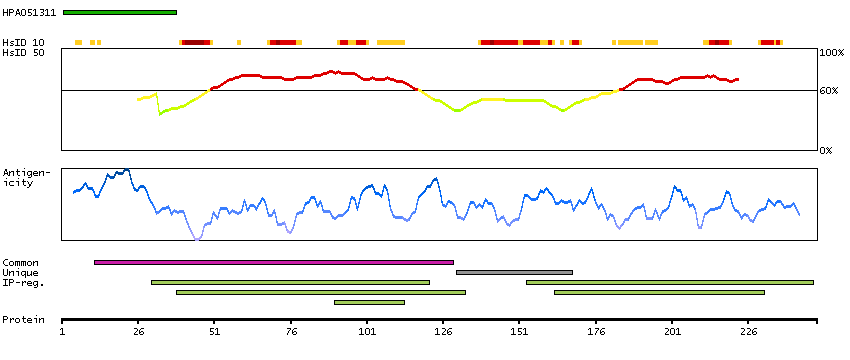
P06730 [Direct mapping] Eukaryotic translation initiation factor 4E
Show all
SCAMPI predicted membrane proteins Predicted intracellular proteins Plasma proteins Cancer-related genes Candidate cancer biomarkers Disease related genes Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)