We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
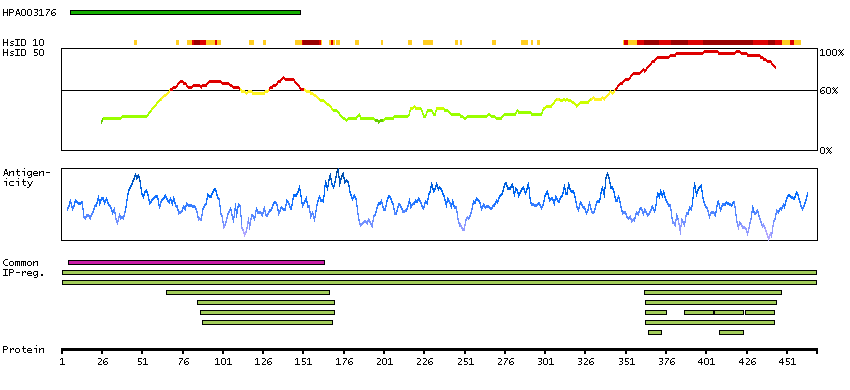
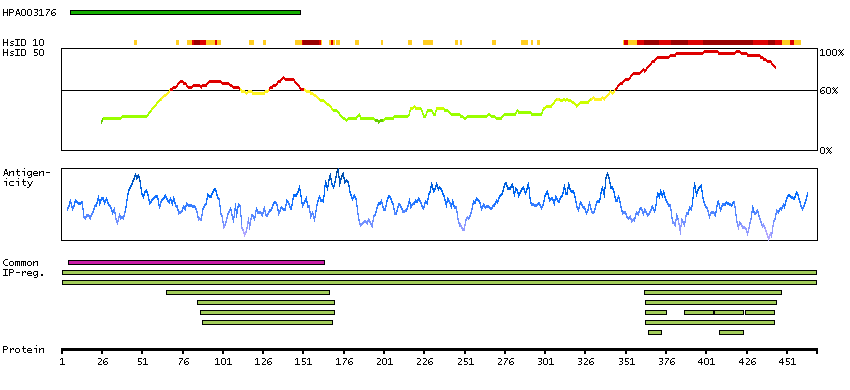
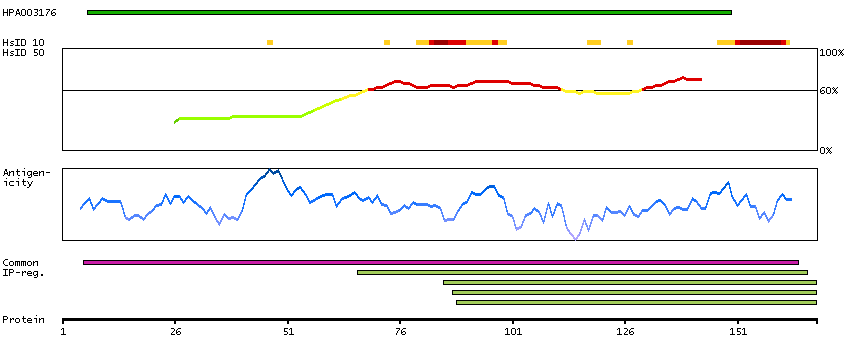
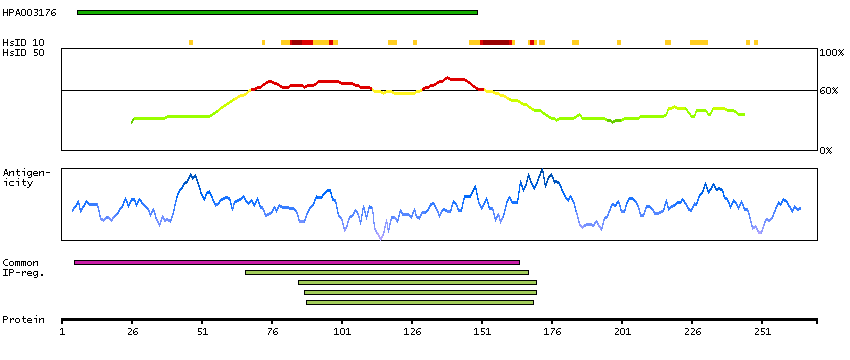
This gene encodes a transcription factor which regulates genes involved in development and apoptosis. The encoded protein is also a protooncogene and shown to be involved in regulation of telomerase. A pseudogene of this gene is located on the X chromosome. Alternative splicing results in multiple transcript variants. [provided by RefSeq, Jan 2012]