We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
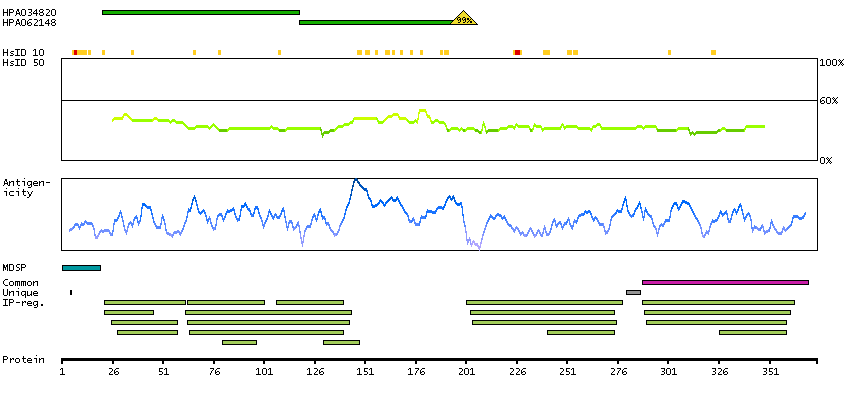
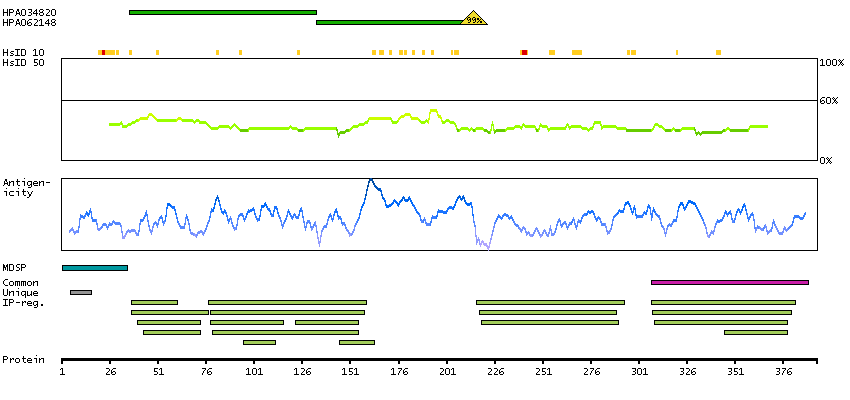
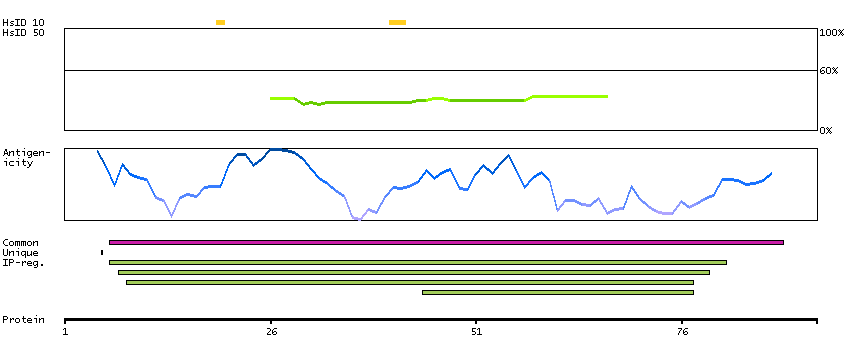
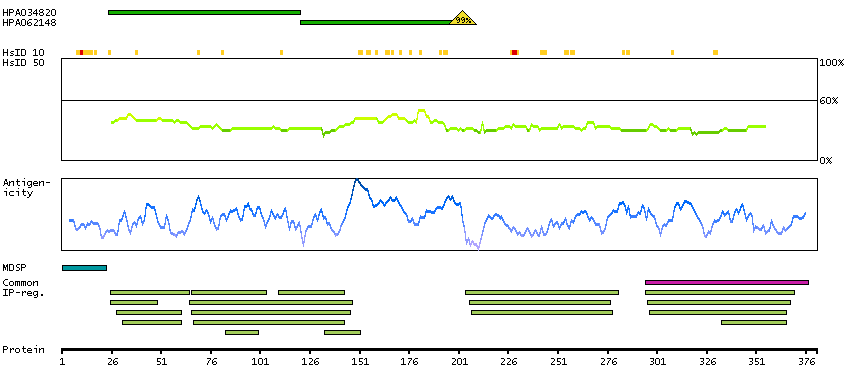
This gene encodes the pulmonary-associated surfactant protein B (SPB), an amphipathic surfactant protein essential for lung function and homeostasis after birth. Pulmonary surfactant is a surface-active lipoprotein complex composed of 90% lipids and 10% proteins which include plasma proteins and apolipoproteins SPA, SPB, SPC and SPD. The surfactant is secreted by the alveolar cells of the lung and maintains the stability of pulmonary tissue by reducing the surface tension of fluids that coat the lung. The SPB enhances the rate of spreading and increases the stability of surfactant monolayers in vitro. Multiple mutations in this gene have been identified, which cause pulmonary surfactant metabolism dysfunction type 1, also called pulmonary alveolar proteinosis due to surfactant protein B deficiency, and are associated with fatal respiratory distress in the neonatal period. Alternatively spliced transcript variants encoding the same protein have been identified.[provided by RefSeq, Feb 2010]