We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
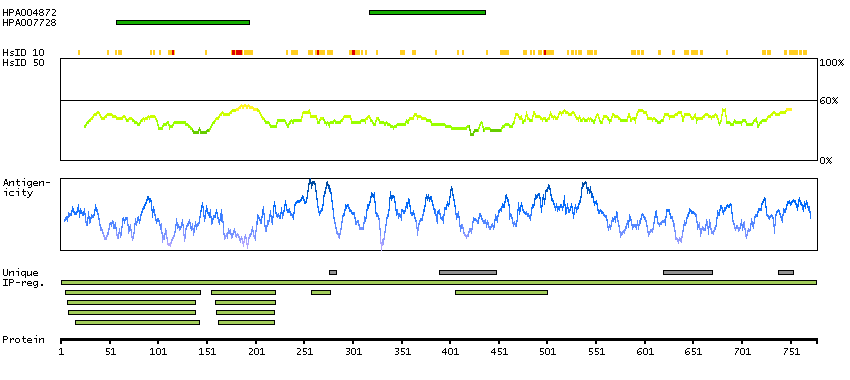
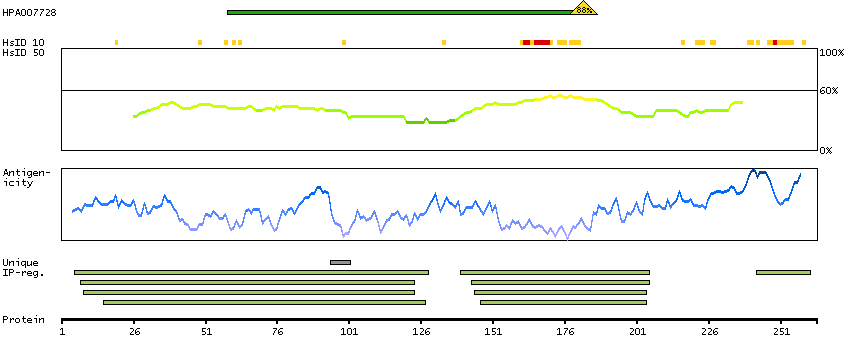
The protein encoded by this gene regulates endosomal sorting and plays a critical role in the recycling and degradation of membrane receptors. The encoded protein sorts monoubiquitinated membrane proteins into the multivesicular body, targeting these proteins for lysosome-dependent degradation. [provided by RefSeq, Dec 2010]