We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
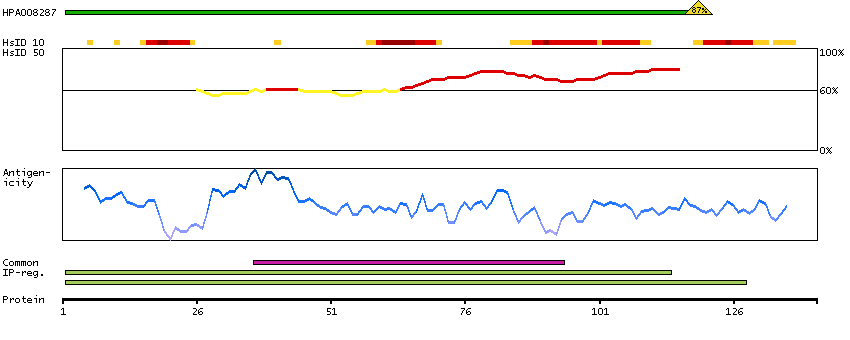
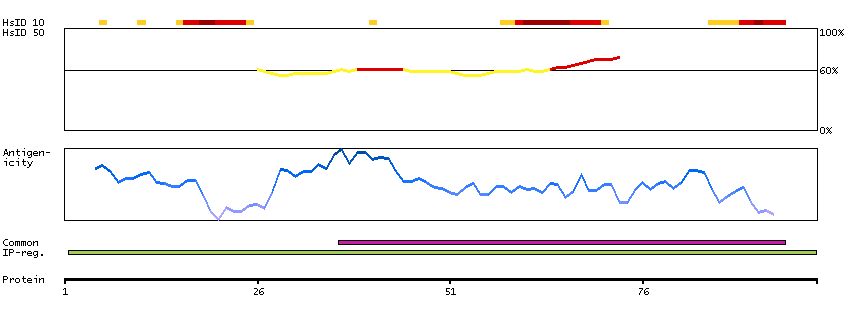
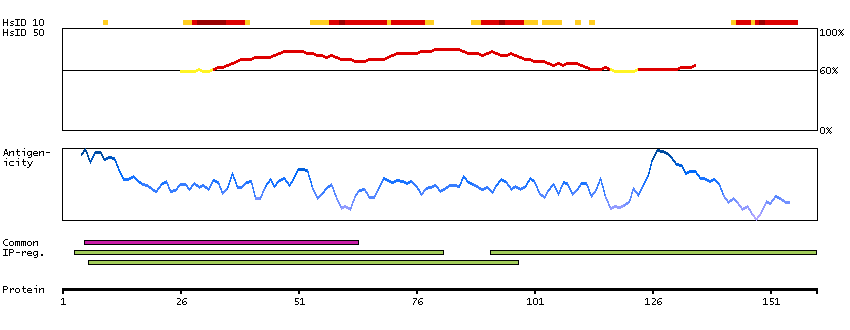
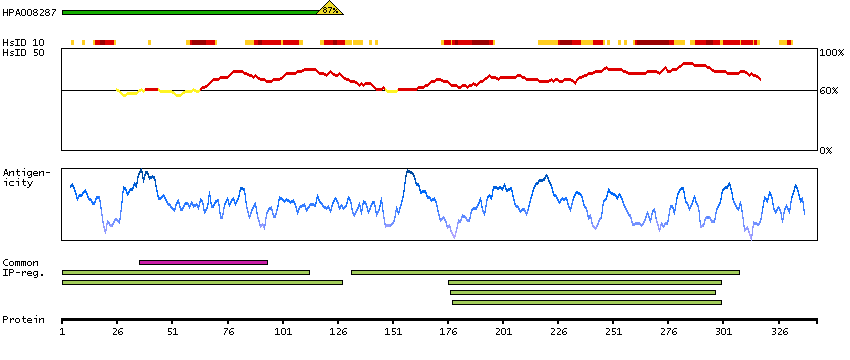
This gene encodes a member of the pyruvate dehydrogenase kinase family. The encoded protein phosphorylates pyruvate dehydrogenase, down-regulating the activity of the mitochondrial pyruvate dehydrogenase complex. Overexpression of this gene may play a role in both cancer and diabetes. Alternatively spliced transcript variants encoding multiple isoforms have been observed for this gene. [provided by RefSeq, Dec 2010]
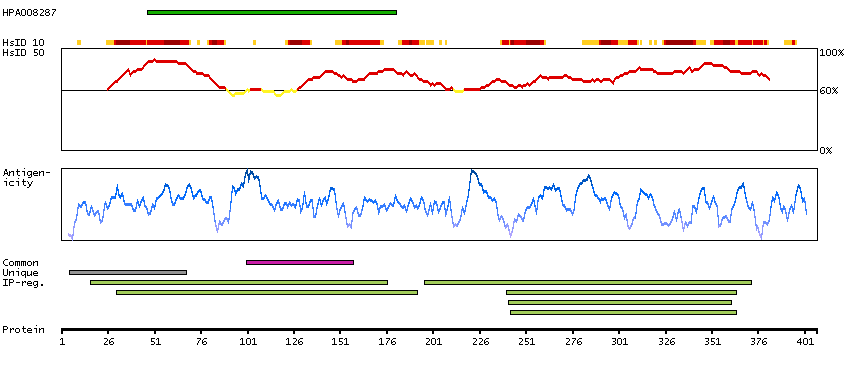
Enzymes ENZYME proteins Transferases Kinases Atypical kinases Predicted intracellular proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
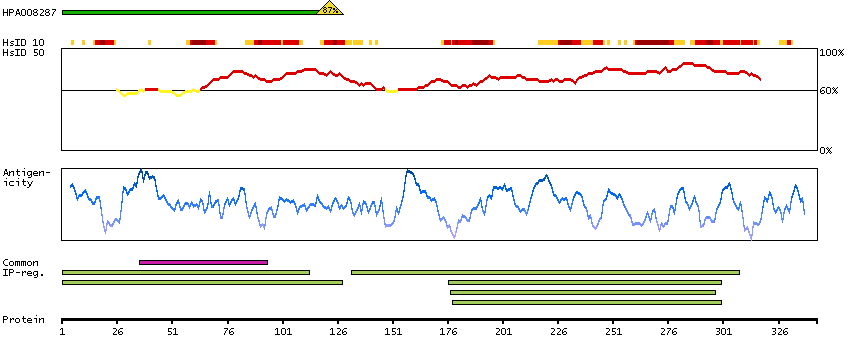
Enzymes ENZYME proteins Transferases Kinases Atypical kinases Predicted intracellular proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004740 [pyruvate dehydrogenase (acetyl-transferring) kinase activity] GO:0005524 [ATP binding] GO:0005654 [nucleoplasm] GO:0005737 [cytoplasm] GO:0005739 [mitochondrion] GO:0005759 [mitochondrial matrix] GO:0005967 [mitochondrial pyruvate dehydrogenase complex] GO:0006006 [glucose metabolic process] GO:0006090 [pyruvate metabolic process] GO:0006111 [regulation of gluconeogenesis] GO:0006468 [protein phosphorylation] GO:0006885 [regulation of pH] GO:0008286 [insulin receptor signaling pathway] GO:0010510 [regulation of acetyl-CoA biosynthetic process from pyruvate] GO:0010565 [regulation of cellular ketone metabolic process] GO:0010906 [regulation of glucose metabolic process] GO:0031670 [cellular response to nutrient] GO:0034614 [cellular response to reactive oxygen species] GO:0042593 [glucose homeostasis] GO:0042803 [protein homodimerization activity] GO:0044237 [cellular metabolic process] GO:0044281 [small molecule metabolic process] GO:0072332 [intrinsic apoptotic signaling pathway by p53 class mediator]
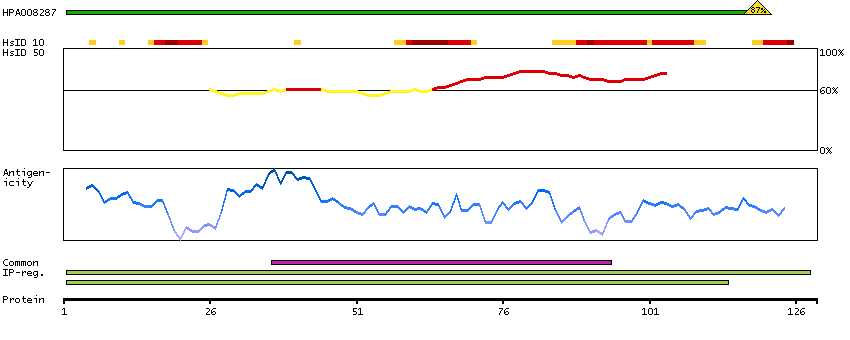
Enzymes ENZYME proteins Transferases Kinases Atypical kinases Predicted intracellular proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)
Show all
GO:0004672 [protein kinase activity] GO:0004740 [pyruvate dehydrogenase (acetyl-transferring) kinase activity] GO:0005524 [ATP binding] GO:0005654 [nucleoplasm] GO:0005737 [cytoplasm] GO:0005739 [mitochondrion] GO:0005759 [mitochondrial matrix] GO:0005967 [mitochondrial pyruvate dehydrogenase complex] GO:0006006 [glucose metabolic process] GO:0006090 [pyruvate metabolic process] GO:0006111 [regulation of gluconeogenesis] GO:0006468 [protein phosphorylation] GO:0006885 [regulation of pH] GO:0008286 [insulin receptor signaling pathway] GO:0010510 [regulation of acetyl-CoA biosynthetic process from pyruvate] GO:0010565 [regulation of cellular ketone metabolic process] GO:0010906 [regulation of glucose metabolic process] GO:0031670 [cellular response to nutrient] GO:0034614 [cellular response to reactive oxygen species] GO:0042593 [glucose homeostasis] GO:0042803 [protein homodimerization activity] GO:0044237 [cellular metabolic process] GO:0044281 [small molecule metabolic process] GO:0072332 [intrinsic apoptotic signaling pathway by p53 class mediator]