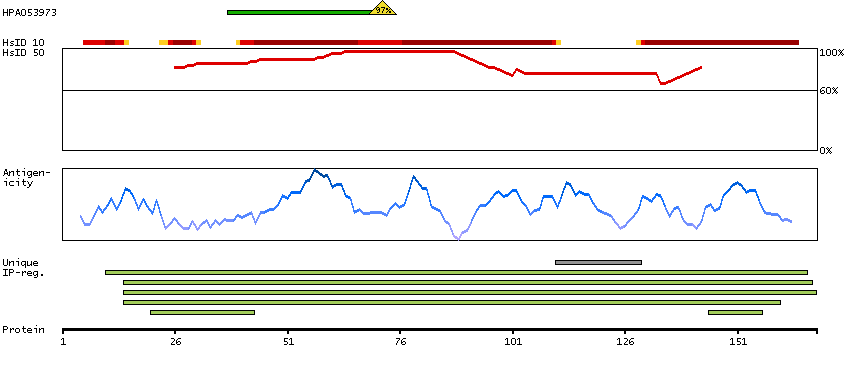
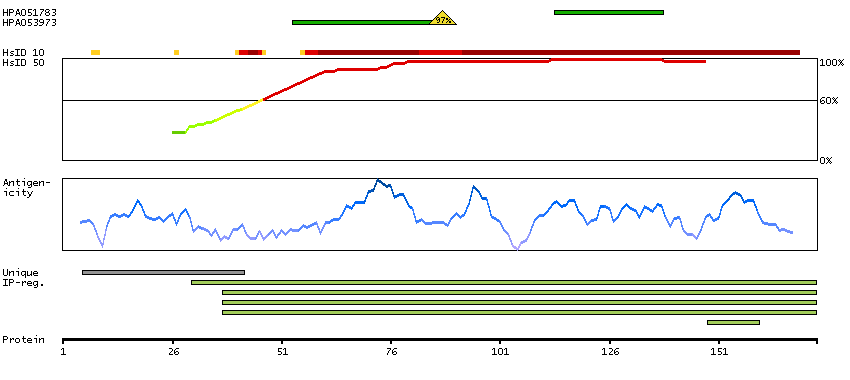
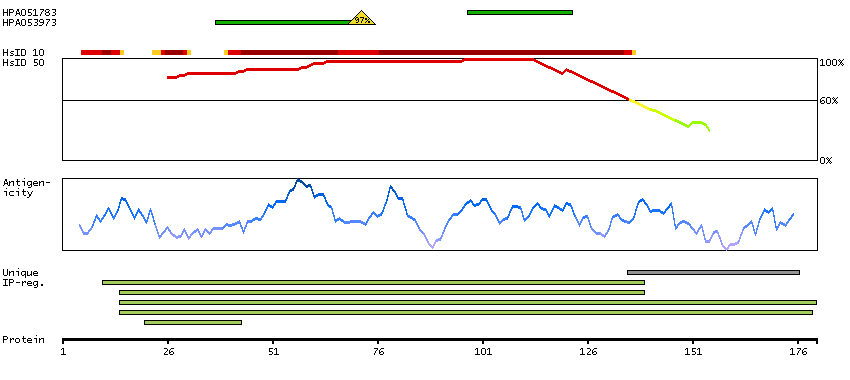
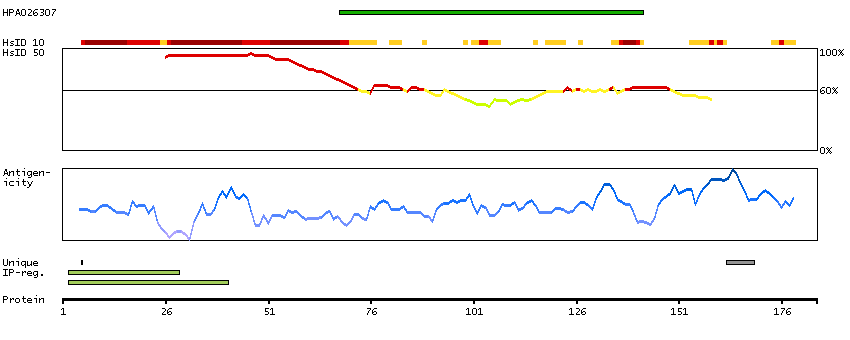
We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Calcium/calmodulin-dependent protein kinase II beta (HGNC Symbol)
Entrez gene summary
The product of this gene belongs to the serine/threonine protein kinase family and to the Ca(2+)/calmodulin-dependent protein kinase subfamily. Calcium signaling is crucial for several aspects of plasticity at glutamatergic synapses. In mammalian cells, the enzyme is composed of four different chains: alpha, beta, gamma, and delta. The product of this gene is a beta chain. It is possible that distinct isoforms of this chain have different cellular localizations and interact differently with calmodulin. Alternative splicing results in multiple transcript variants. [provided by RefSeq, May 2014]
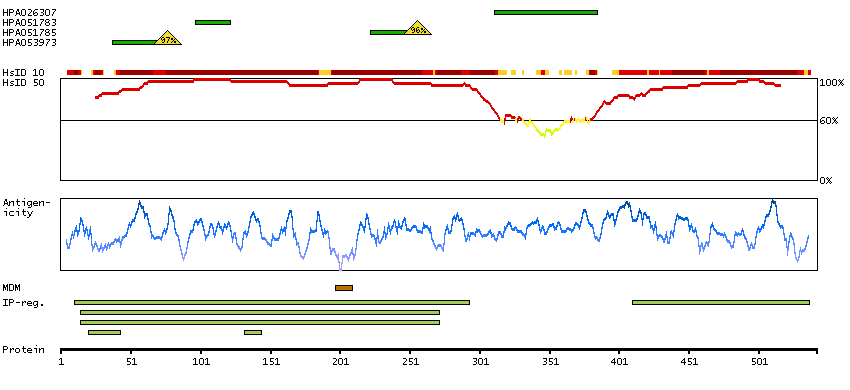
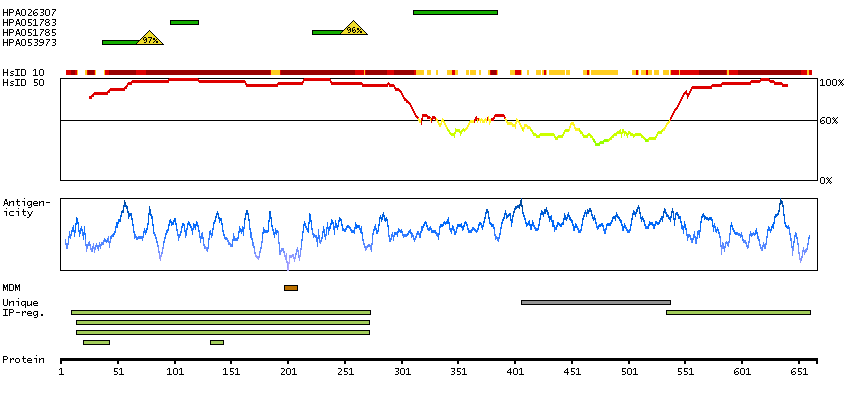
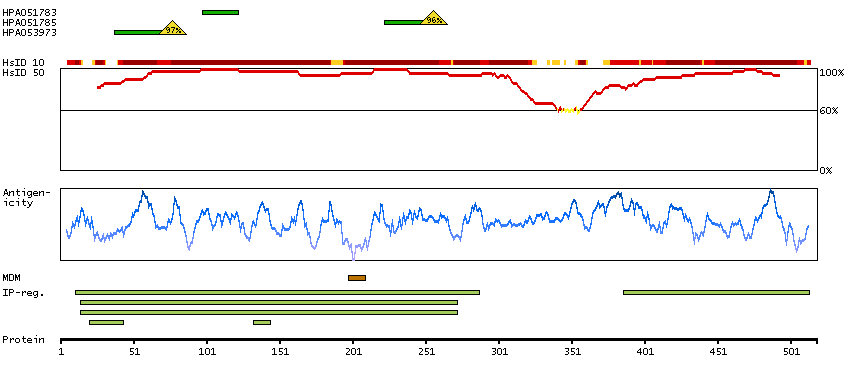
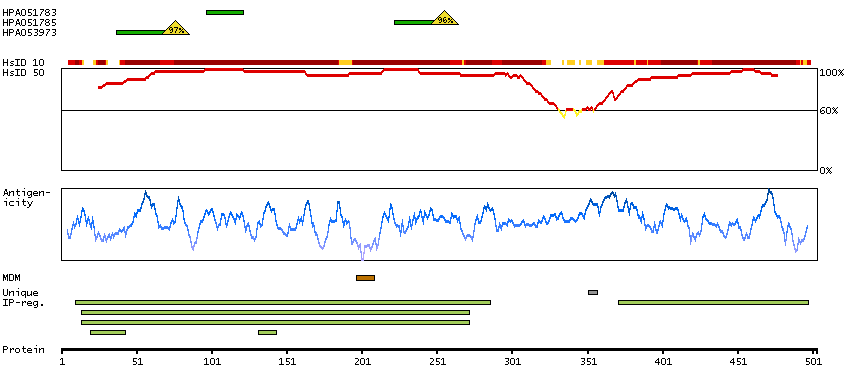
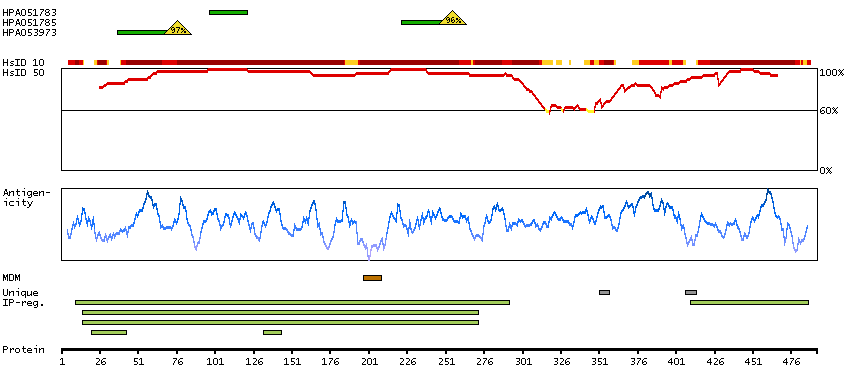
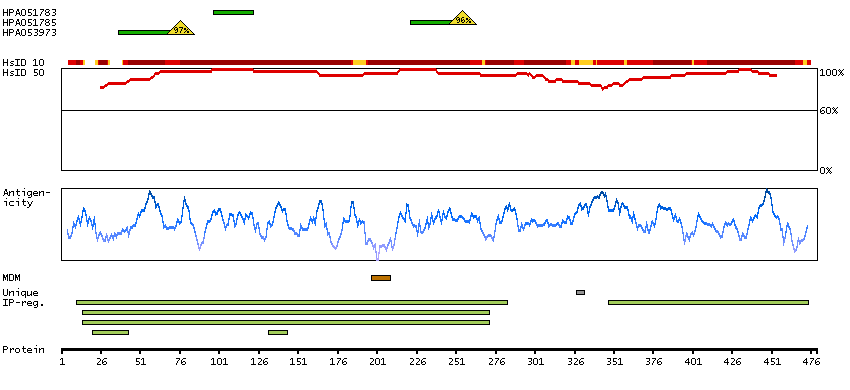
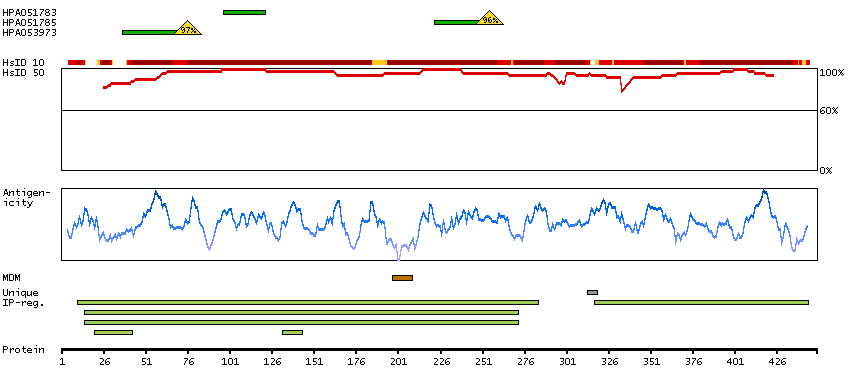
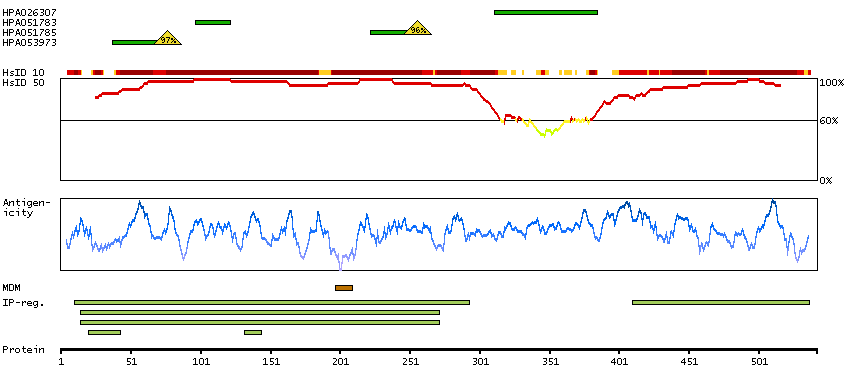
Q13554 [Direct mapping] Calcium/calmodulin-dependent protein kinase type II subunit beta A4D2J9 [Target identity:100%; Query identity:100%] Calcium/calmodulin-dependent protein kinase (CaM kinase) II beta
Show all
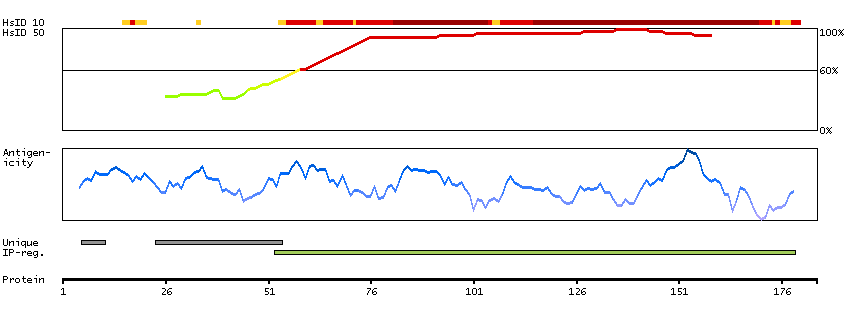
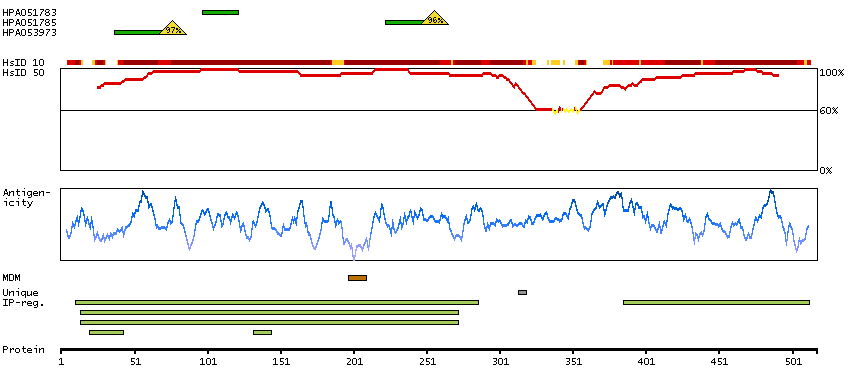
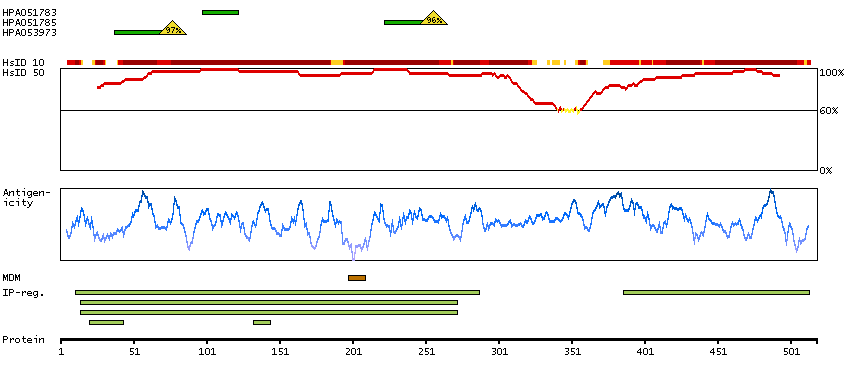
Enzymes ENZYME proteins Transferases Kinases CAMK Ser/Thr protein kinases Predicted membrane proteins Prediction method-based Membrane proteins predicted by MDM MEMSAT-SVM predicted membrane proteins Phobius predicted membrane proteins SCAMPI predicted membrane proteins SPOCTOPUS predicted membrane proteins THUMBUP predicted membrane proteins # TM segments-based 1TM proteins predicted by MDM Plasma proteins Protein evidence (Kim et al 2014) Protein evidence (Ezkurdia et al 2014)