We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
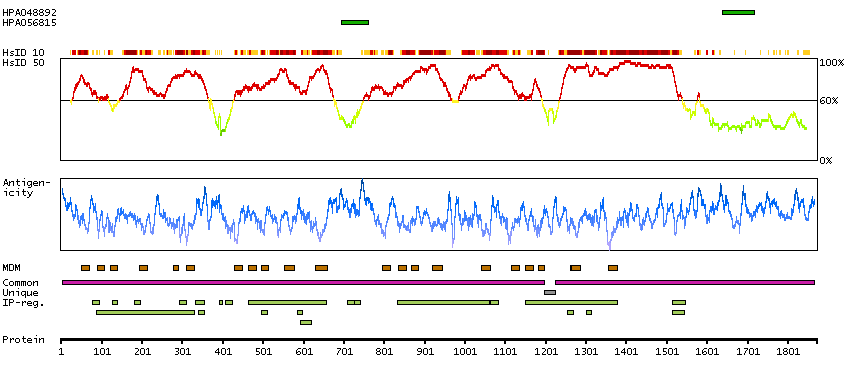
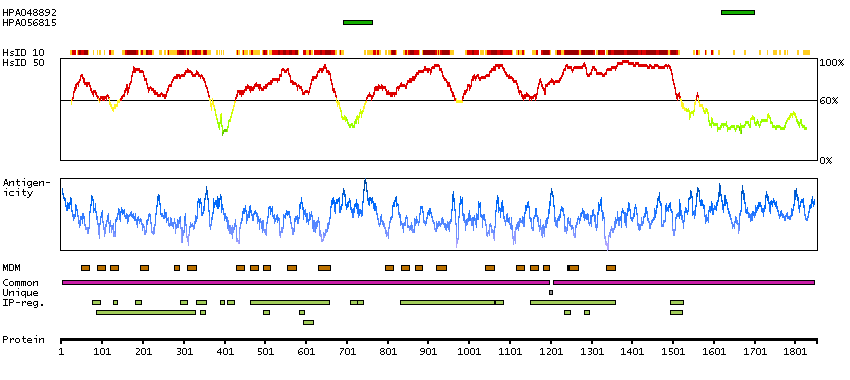
Calcium channel, voltage-dependent, L type, alpha 1S subunit (HGNC Symbol)
Entrez gene summary
This gene encodes one of the five subunits of the slowly inactivating L-type voltage-dependent calcium channel in skeletal muscle cells. Mutations in this gene have been associated with hypokalemic periodic paralysis, thyrotoxic periodic paralysis and malignant hyperthermia susceptibility. [provided by RefSeq, Jul 2008]