We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
Calcium channel, voltage-dependent, L type, alpha 1F subunit
Protein class
Disease related genes FDA approved drug targets Plasma proteins Predicted intracellular proteins Predicted membrane proteins Transporters Voltage-gated ion channels
Calcium channel, voltage-dependent, L type, alpha 1F subunit (HGNC Symbol)
Entrez gene summary
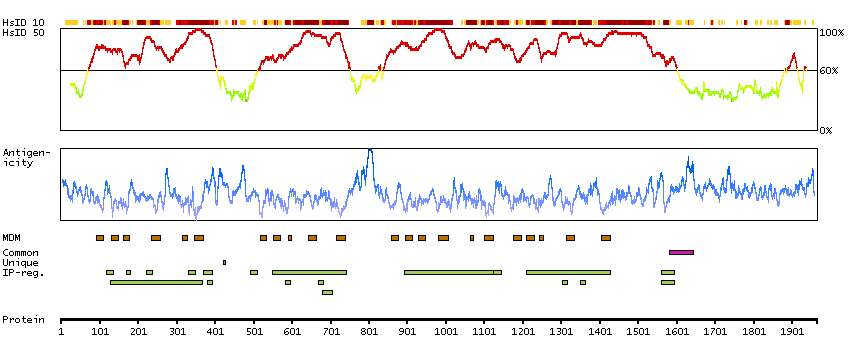
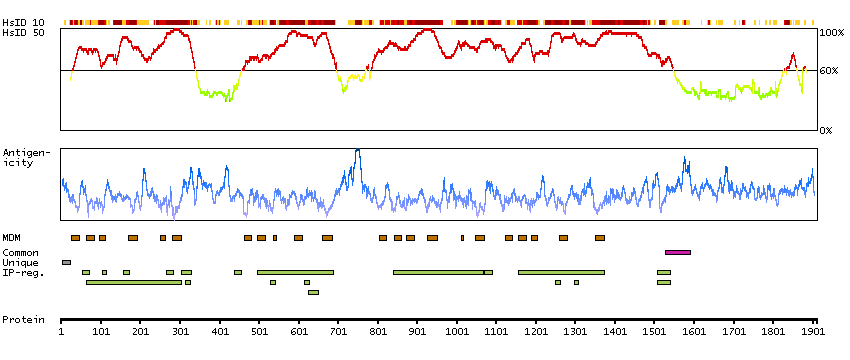
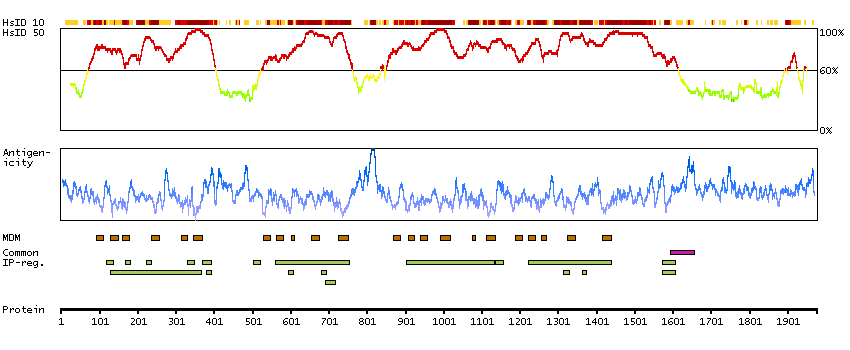
This gene encodes a multipass transmembrane protein that functions as an alpha-1 subunit of the voltage-dependent calcium channel, which mediates the influx of calcium ions into the cell. The encoded protein forms a complex of alpha-1, alpha-2/delta, beta, and gamma subunits in a 1:1:1:1 ratio. Mutations in this gene can cause X-linked eye disorders, including congenital stationary night blindness type 2A, cone-rod dystropy, and Aland Island eye disease. Alternatively spliced transcript variants encoding multiple isoforms have been observed. [provided by RefSeq, Aug 2013]