We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
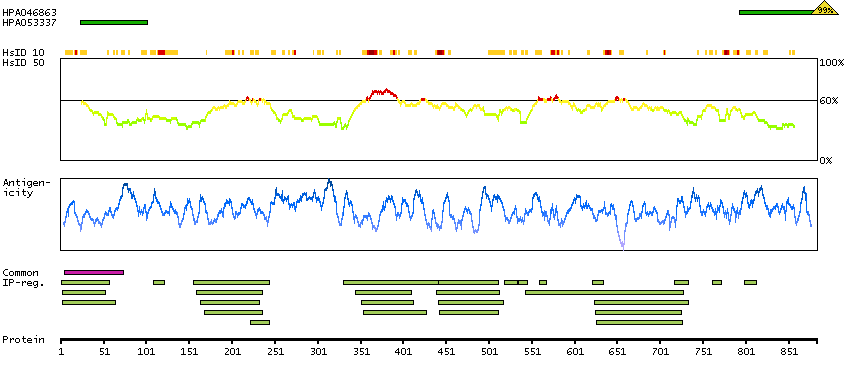
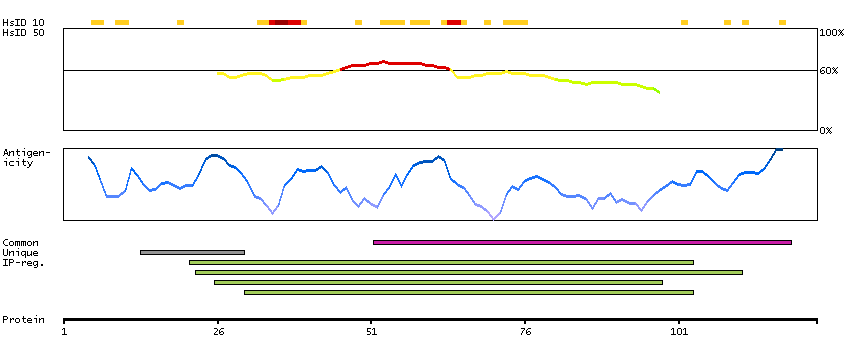
The protein encoded by this gene is a member of the membrane-associated guanylate kinase-like (MAGUK) protein family which is characterized by members having multiple PDZ domains, a single SH3 domain, and a single guanylate kinase-like (GUK)-domain. In addition, members of the zonula occludens protein subfamily have an acidic domain, a basic arginine-rich region, and a proline-rich domain. The protein encoded by this gene plays a role in the linkage between the actin cytoskeleton and tight-junctions and also sequesters cyclin D1 at tight junctions during mitosis. Alternative splicing results in multiple transcript variants encoding distinct isoforms. This gene has a partial pseudogene on chromosome 1. [provided by RefSeq, May 2012]