We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
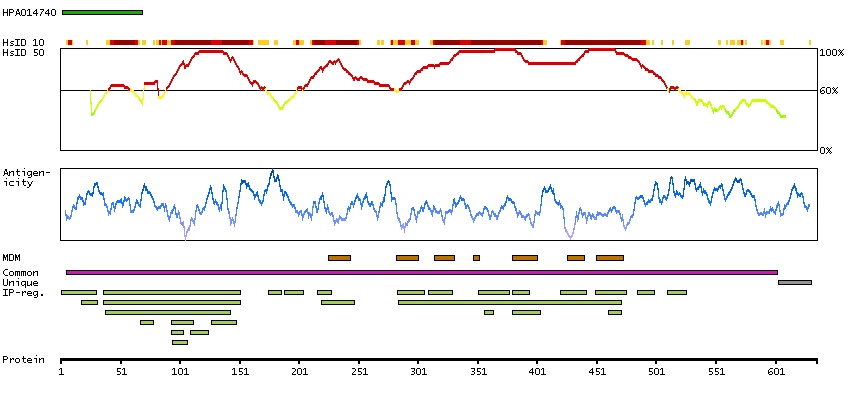
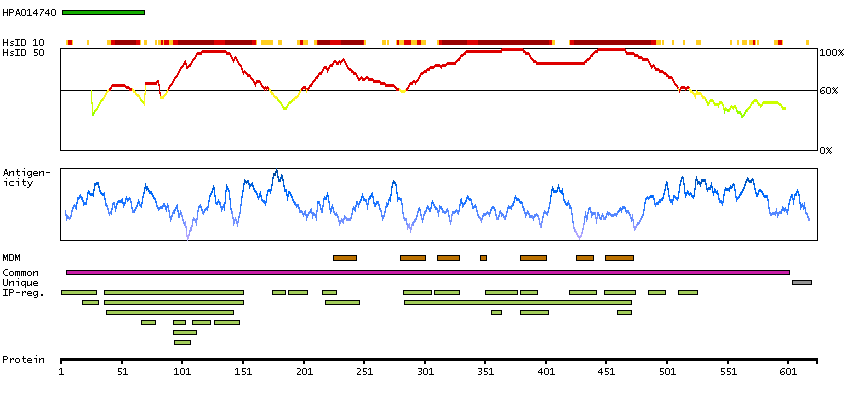
Potassium channel, voltage gated Shaw related subfamily C, member 4 (HGNC Symbol)
Entrez gene summary
The Shaker gene family of Drosophila encodes components of voltage-gated potassium channels and is comprised of four subfamilies. Based on sequence similarity, this gene is similar to the Shaw subfamily. The protein encoded by this gene belongs to the delayed rectifier class of channel proteins and is an integral membrane protein that mediates the voltage-dependent potassium ion permeability of excitable membranes. It generates atypical voltage-dependent transient current that may be important for neuronal excitability. Multiple transcript variants have been found for this gene. [provided by RefSeq, Jul 2010]