We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
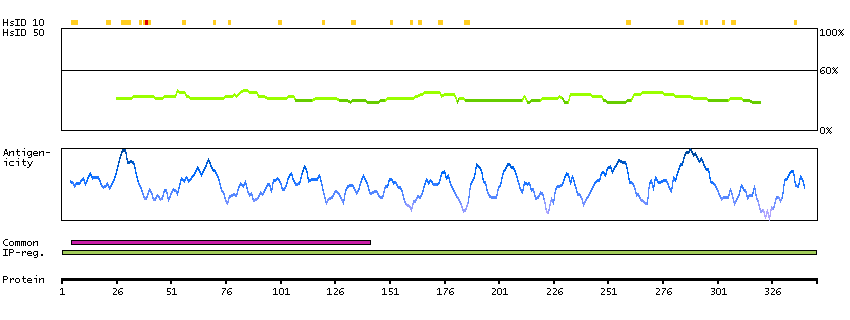
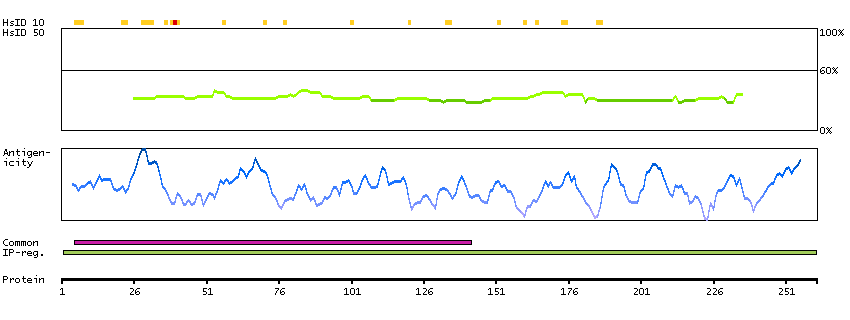
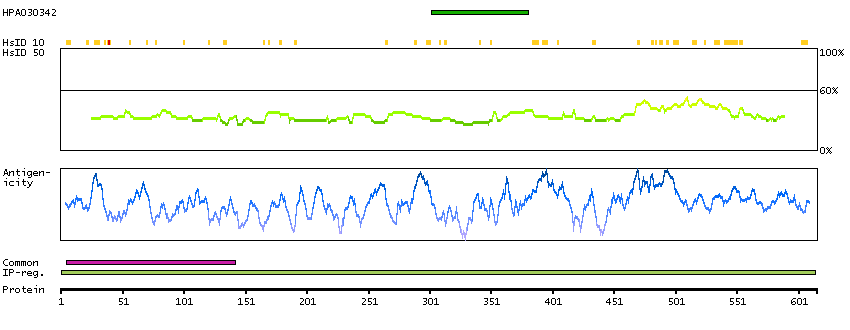
This gene encodes menin, a putative tumor suppressor associated with a syndrome known as multiple endocrine neoplasia type 1. In vitro studies have shown menin is localized to the nucleus, possesses two functional nuclear localization signals, and inhibits transcriptional activation by JunD, however, the function of this protein is not known. Two messages have been detected on northern blots but the larger message has not been characterized. Alternative splicing results in multiple transcript variants. [provided by RefSeq, Oct 2008]