We use cookies to enhance the usability of our website. If you continue, we'll assume that you are happy to receive all cookies. More information. Don't show this again.
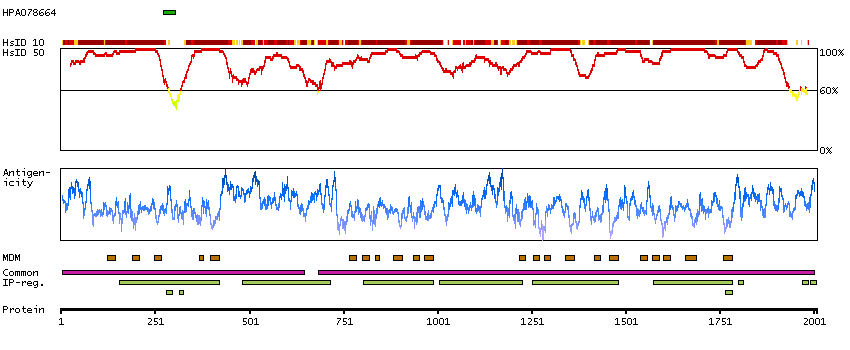
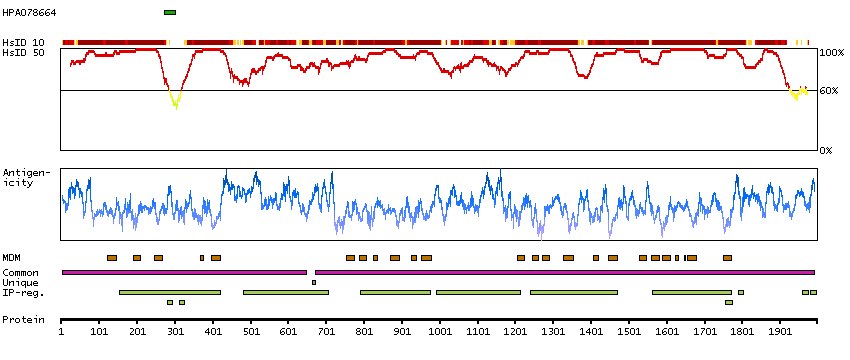
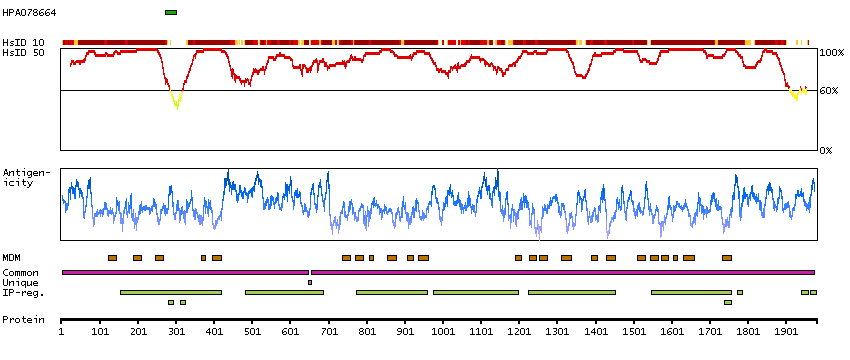
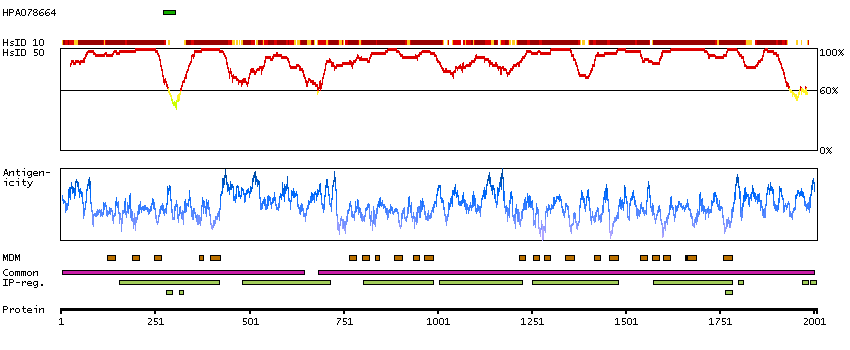
Sodium channel, voltage gated, type I alpha subunit (HGNC Symbol)
Entrez gene summary
Voltage-dependent sodium channels are heteromeric complexes that regulate sodium exchange between intracellular and extracellular spaces and are essential for the generation and propagation of action potentials in muscle cells and neurons. Each sodium channel is composed of a large pore-forming, glycosylated alpha subunit and two smaller beta subunits. This gene encodes a sodium channel alpha subunit, which has four homologous domains, each of which contains six transmembrane regions. Allelic variants of this gene are associated with generalized epilepsy with febrile seizures and epileptic encephalopathy. Alternative splicing results in multiple transcript variants. The RefSeq Project has decided to create four representative RefSeq records. Three of the transcript variants are supported by experimental evidence and the fourth contains alternate 5' untranslated exons, the exact combination of which have not been experimentally confirmed for the full-length transcript. [provided by RefSeq, Oct 2015]